

Breaking Prod #2 - Building Search at Discord
Understanding the architecture that enables search at global scale


Welcome to Breaking Prod, a monthly series where I try to break down some of the most interesting systems, architectures, or bugs from the world of production-scale tech.
A quick disclaimer: I haven’t worked on these systems myself (not yet!), and I don’t claim deep expertise. I’m just someone who's genuinely curious and wants to learn by dissecting. These posts are my way of doing that, by breaking things down in public and trying to build an intuitive understanding along the way.
These posts are not meant to be overly academic or loaded with technical jargons. The idea is to build an intuitive understanding of WHY these systems exist, what problems they solve, and HOW they actually work, all in a way that’s natural and intuitive.
Some analogies may not be perfect. But that’s the trade-off I’m okay with, I want even someone with just a bit of tech curiosity to read through and feel like they “get it”, just like I did.
Today, we are going to look at how Discord implemented its highly requested search feature. Knowing Discord, you might know the scale at which it operates; a Discord server can have millions of users, each sending thousands of messages every second.
It’s a fascinating design, with all its consideration of cost, efficiency, and simplicity.
Requirements
Let’s look at the requirements for a search system, specific to Discord.
Cost-effective — This is the core requirement. Text and voice chat are the core features for Discord, with search being an accessory feature. That means it should not cost more than it would cost for actually storing the messages.
Fast and responsive — All the features Discord provides are quick, intuitive. Search should be as fast as well.
Self-healing — Meaning if something goes wrong, it should be able to self-heal, without requiring much intervention.
Linearly scalable — If there are more messages, we should be able to just add more clusters, and it should be enough.
Lazily-indexed — Not everyone uses search, meaning we shouldn’t index messages unless someone attempts to search them at least once. Also, if an index fails, we need to be able to re-index servers on the fly.
Discord searched for multiple open-source alternatives and went with ElasticSearch; a few of the reasons include built-in Zen service discovery, built-in structured query DSL, and the fact that engineers had more experience with it.
Elastic Search Internal
To truly understand why Discord went with ElasticSearch, we need to understand how ElasticSearch works internally and why that would be beneficial for Discord in implementing their search system.
Let’s try to understand how to approach a text-based search system.
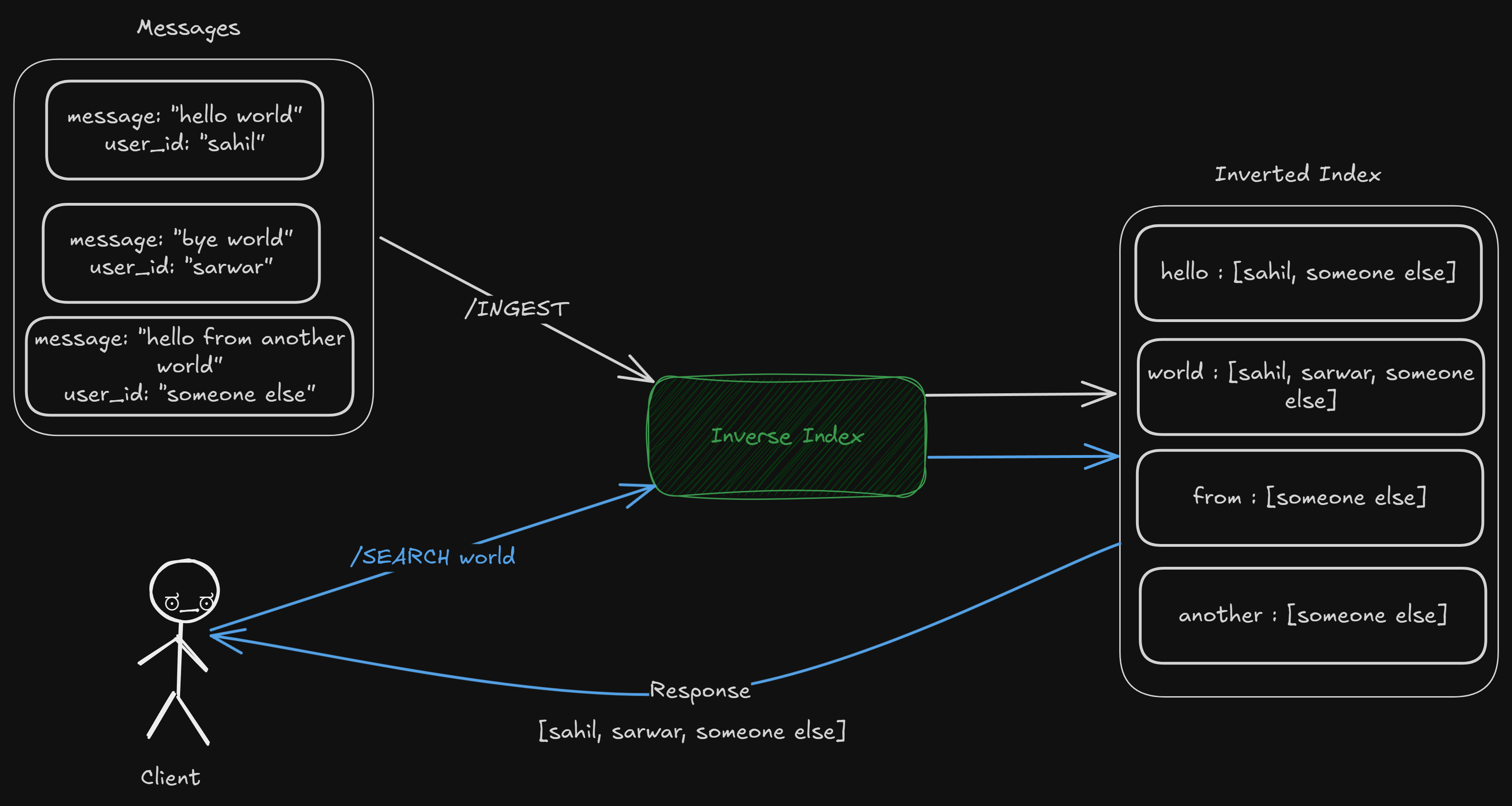
Inverted Index
We need to be able to perform the following —
First, we ingest the messages to enable search on them later.
/INGEST [{message : “hello world”, user_id : “sahil”}, {message : “bye world”, user_id : “sarwar”}, {message : “hello from another world”, user_id : “someone_else”}]
Then, when we search for some word, it should return the corresponding fields (assuming user_id in our case)
/SEARCH {text : “world”} → [“sahil”, “sarwar”, “someone_else”]
/SEARCH {text : “another”} → [“someone_else”]
We need to be able to match the “individual words in the messages” to their “corresponding user”; it’s called an “inverted index”.
Tokenizers and Parsers
But we don’t always search for the exact word that we sent. We search for a near, similar word; let’s consider the example below.
Message — “I love Discord.”
Tokenizer splits the message into different tokens — [“i”, “love”, “Discord”]
Token filter modifies the tokens, something like removing fillers (“i”), making everything in lowercase, [“love”, “discord”], transforming words/verbs in their different forms (love → loving, loved)
Due to the smart tokenization and filtration, we get accurate results. Even if we search for near-similar or typo words, we get the desired results.
Lucene Segments
ElasticSearch is built on top of Apache Lucene.
Every time we index a bunch of messages, Lucene writes them into a segment, an immutable file on disk that stores the inverted index, metadata, word frequencies, and more.
Over time, it creates multiple segments. So ElasticSearch periodically merges them for efficiency (like how multiple SSTables are merged in the LSM tree).
The design of Lucene segments is similar to how a write-heavy database is designed, but the inverted index also enables fast searches, making it a great text-based search system.
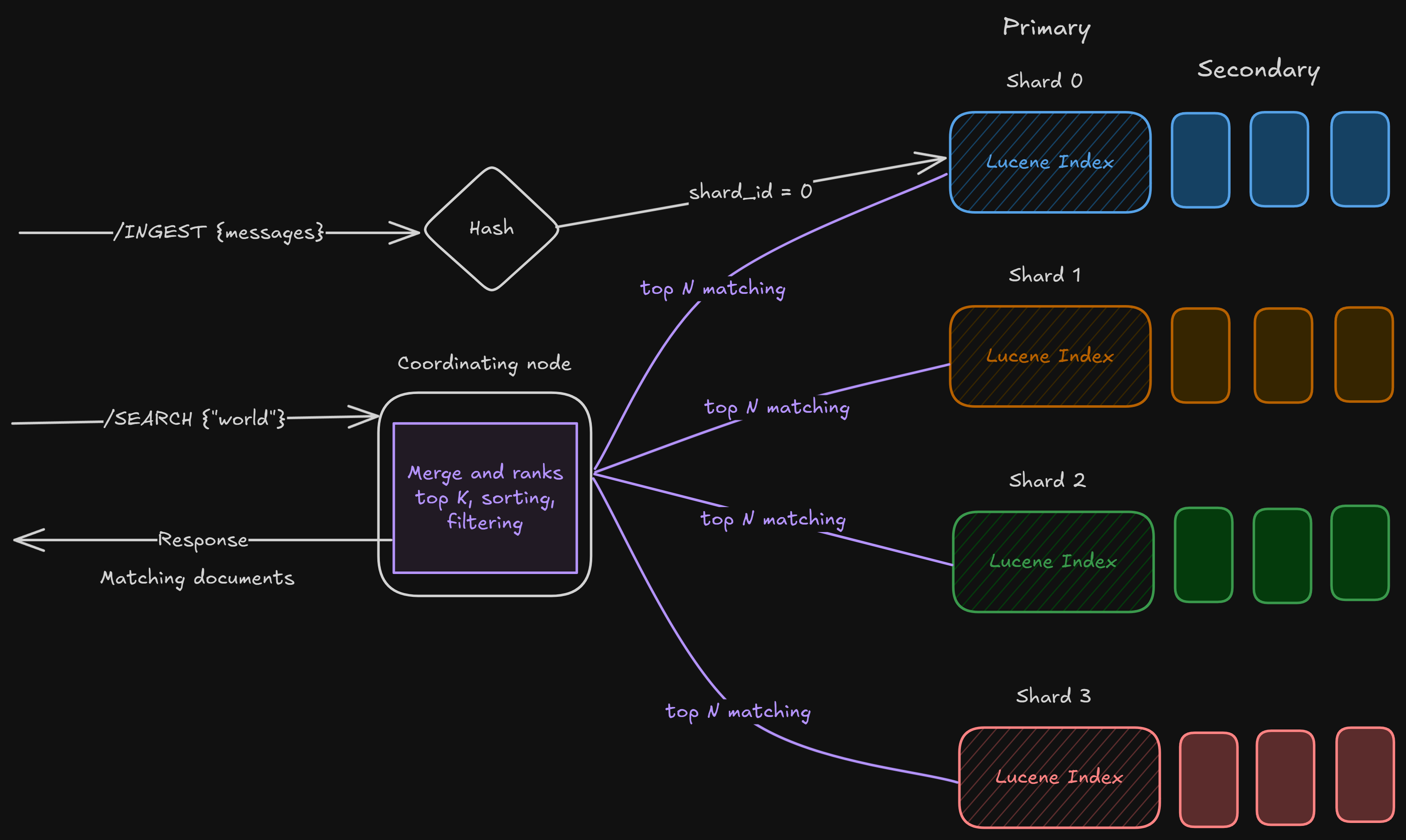
Distributed by Design
ElasticSearch is nothing but a coordinator sitting on top of different shards, each having its own Lucene indexes. It makes sure the queries, ingestion, and querying both go to the relevant shards.
Ingest
We create a routing algorithm so that the messages go to a particular shard. It can be as simple as hash(document_id) % num_shards
Or maybe something complex like channel_id, so that all the indices of a particular channel reside in 1 place.
Search
The way we search for a message is by the text, like “world”. We don’t know to which shard this “world” belongs. So what do we do?
We don’t have any other option than to search in all the shards, get the “top N matching documents” with the word “world”, and then merge, sort, filter, and rank them to return the “top K matching documents”.
We will look at how Discord modified the search path for their advantage.
To know more about ElasticSearch internals, I highly suggest going through this amazing article on it.
Building the Discord Search
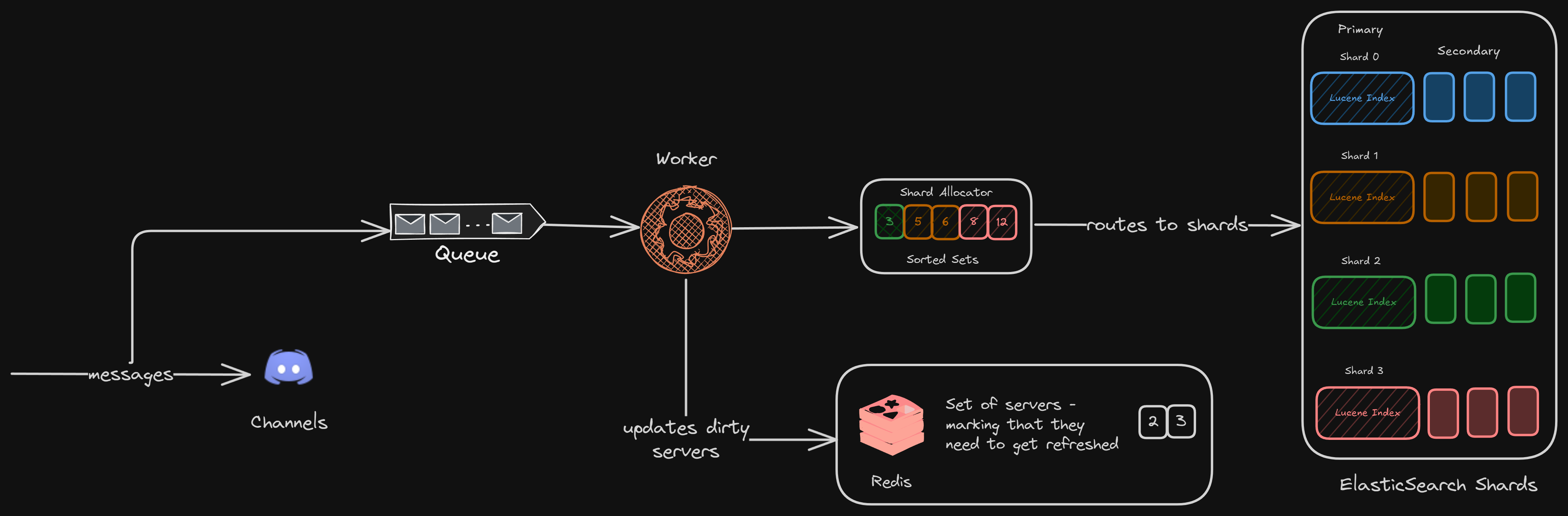
One of the key design decisions that Discord took was handling the sharding and routing to the application layer, allowing them to index messages into a pool of smaller Elasticsearch clusters.
In the event of a cluster outage, only Discord messages contained on the affected cluster would be unavailable for searching.
The advantage of being able to throw away an entire cluster’s data if it becomes unrecoverable (the system can lazily re-index the Discord server the next time a user performs a search).
This also means that all the things that the following operations need to be done at the application level.
When we do
/INGEST, we need to be able to select an appropriate shard on which these messages reside.When we do
/SEARCH, we don’t have to rely on Elastic to go through all the shards, get top N matching, and return top K matching. All these we will have to do ourselves, maybe more efficiently.
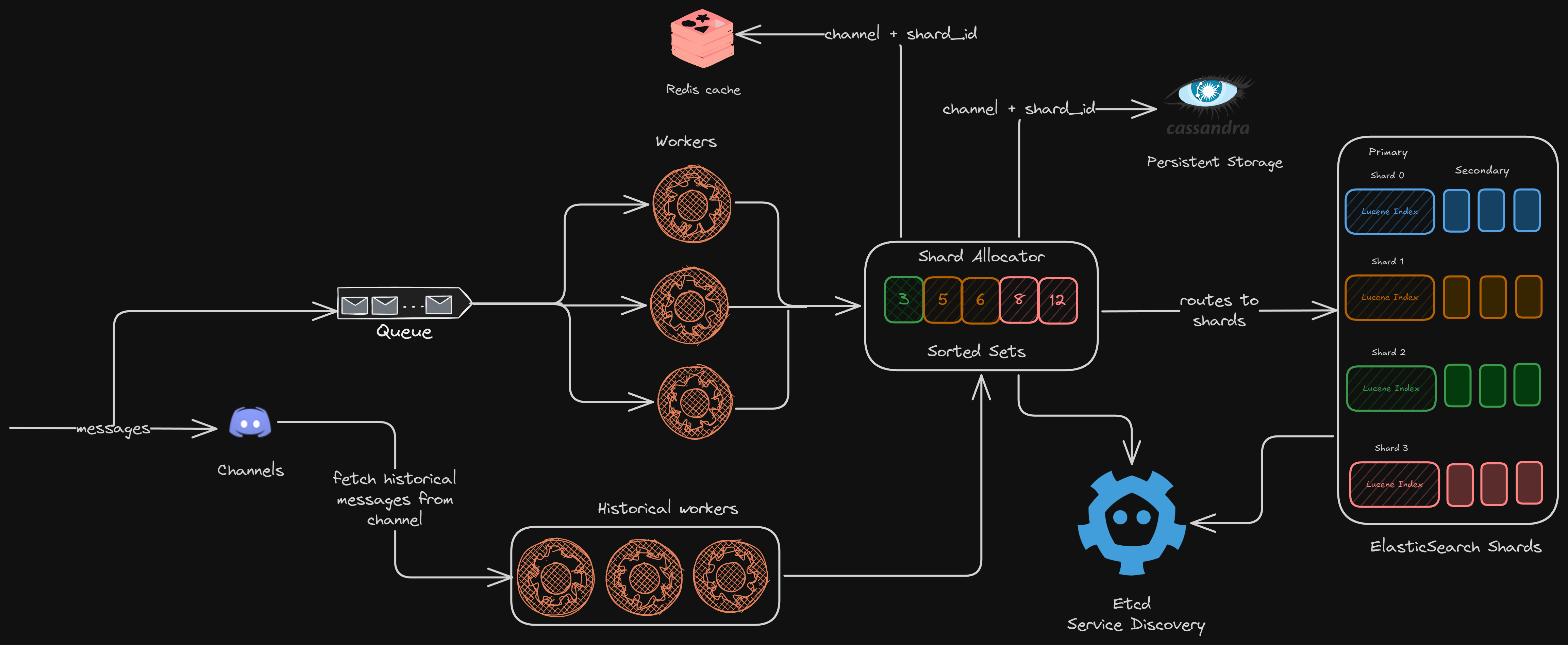
Ingestion Path
ElasticSearch likes to ingest data in bulk. But the messages don’t arrive in bulk; it’s 1 at a time.
Meaning we need some kind of an aggregator that can take multiple messages from a queue, and send them to Elastic to index them in bulk.
This also means there is a lag between when we send the message and when it’s available to search.
But that’s okay, users won’t search for anything that they sent just now.
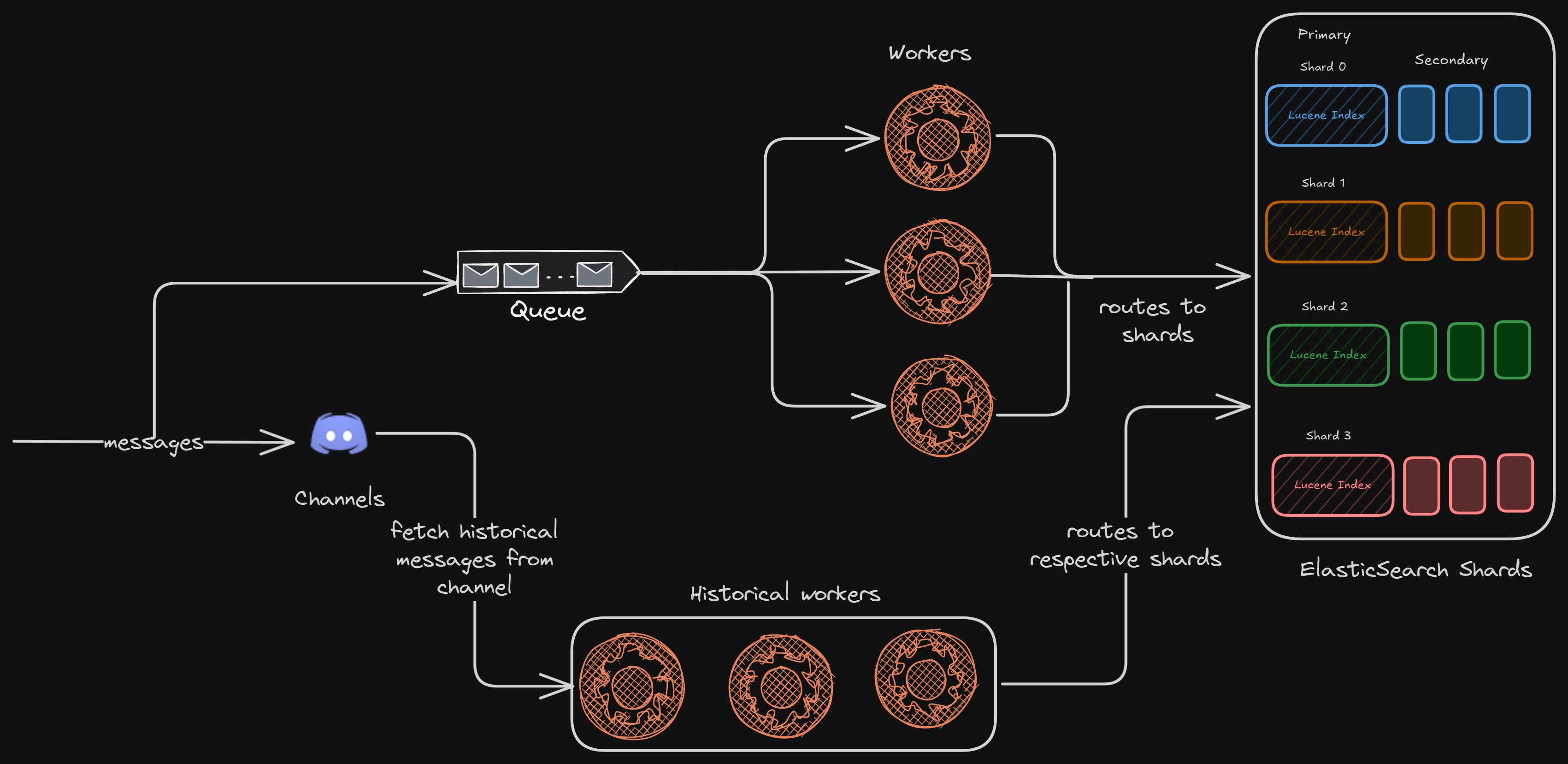
All the real-time messages go to a queue, from where the workers pick them in bulk, route them to different Elastic shards for indexing
For the older messages, there are historical workers in place who take older messages for indexing and routing
Routing
As mentioned before, since the application layer decides all the routing logic (like where the data lives for a channel), we need to be able to get this mapping quickly for ingestion.
We needed a quick and easy mapping of which Elasticsearch shard a Discord server’s messages would reside on. Let’s call this pair channel_id + shard.
We store this pair in Cassandra, which is the persistent storage for Discord
But we also need to get this pair quickly, and for that, we store these mappings in Redis for fast access
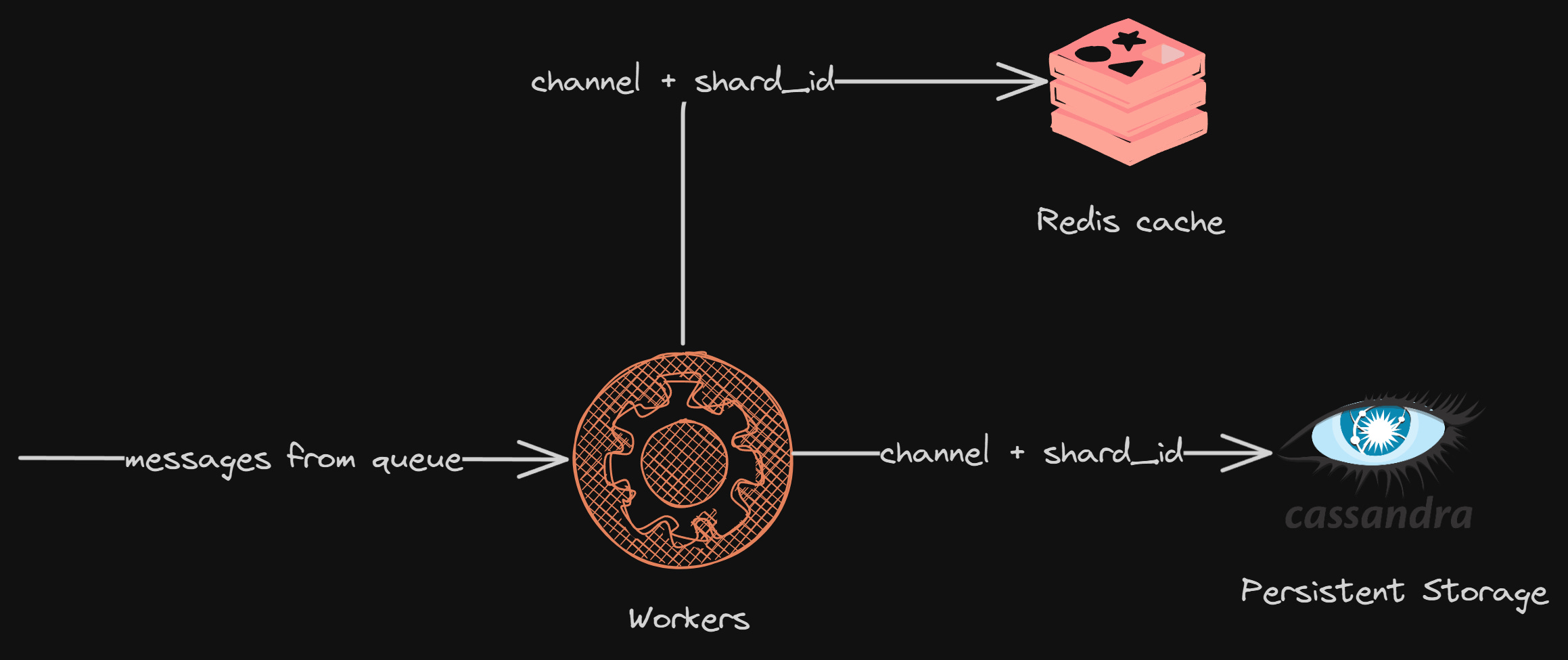
But what happens when a Discord server is indexed for the first time? On which shard should we keep its messages? Since we are handling the routing on the application layer, we can be smart about it.
We can think of it like a load balancer, where each shard will have its current load, and any new indexed messages can be put onto the one with the minimum load.
That’s what Discord did. They kept a load factor associated with all the shards, and when a new request came, we took the lowest load shard, stored the messages, and updated its load.
We can use Redis sorted sets in this case.
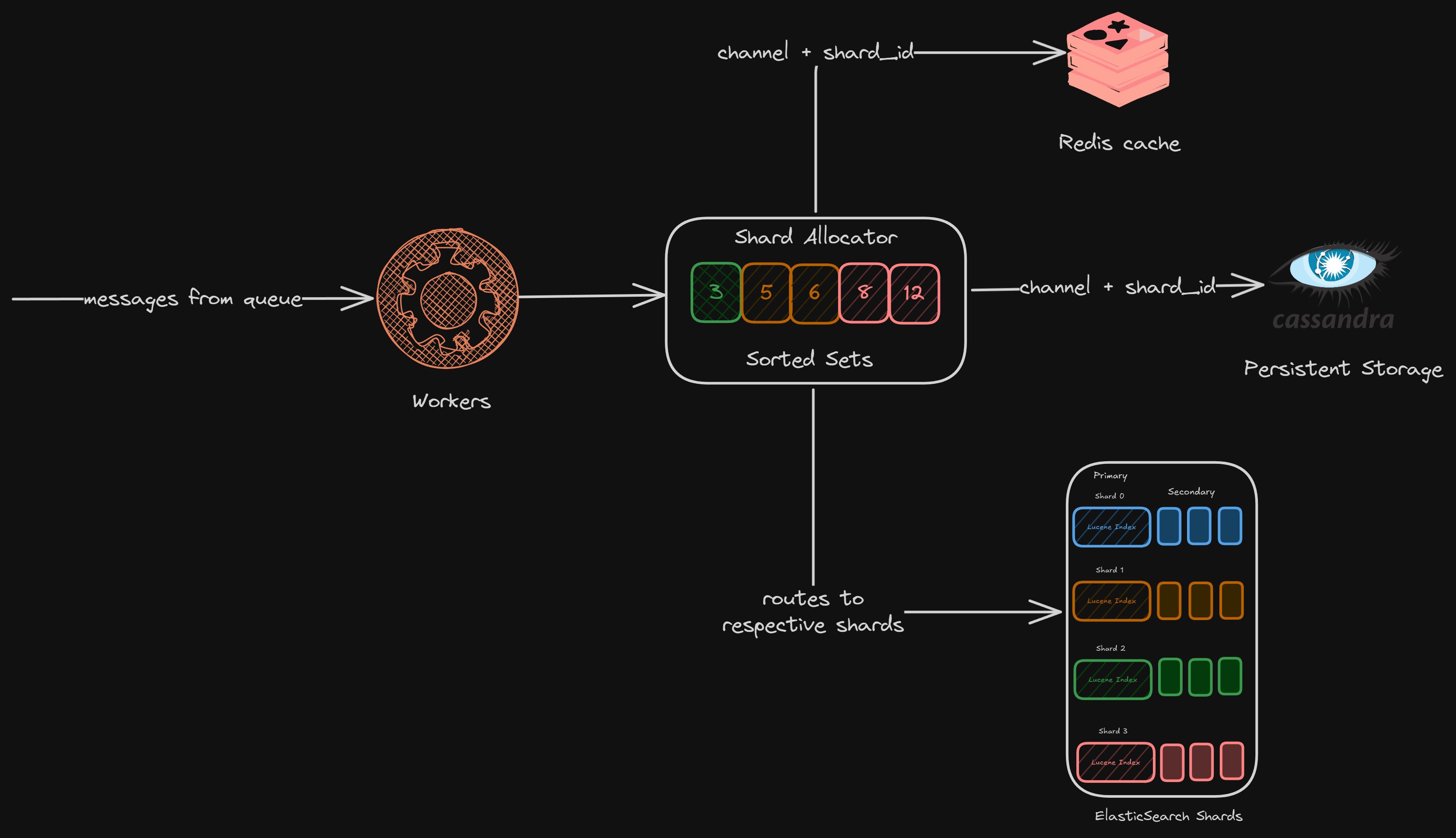
We still have something missing. Since we are dealing with a distributed system, we need some kind of service discovery in between. Discord already uses etcd for service discovery.
Now, here is the final architecture for ingesting messages in Discord.
Storage
As we discussed earlier, one of the main requirements was that we don’t want the search to cost more than actually storing the messages. So, what do we actually store in Elastic?
If we store the entire message and its metadata, it would take a lot of space, and that would cost a lot. We want to store as few things as possible, but still provide the best possible search.
What to index?
This is a really clever optimization that Discord did.
Instead of storing the entire message content, which is not in the format best for text search (they could be JSON or blobs, not ideal for text search), they just stored the metadata for the message.
These are the fields on which we can search in a Discord server, and these are the fields that are stored as an index.
'message_id' -> the actual message id
'channel_id' -> on which channel this message belong to
'guild_id' -> on what server this message exist
'author_id' -> who sent this message
'mentions' -> who does this message mention
'attachment_extensions' -> search on basis of file types .png, .pdfIf you have ever used Discord, you might know that these are the basic types of searches we can perform on any server.
Discord only stores the following in ElasticSearch —
'message_id', 'channel_id', 'guild_id'
Meaning, for every search to Elastic, these are the only fields that can be returned.
But these are not the actual messages, then how do we show the message?
That’s why this is such a clever design. Discord takes these fields, searches for the specific message in Cassandra, and then shows the message in the UI.
But it is inefficient, right? Why make 2 separate calls to show the message?
Cause Discord needs at least a couple of nearby messages to render it in UI, to get the context. That’s a design tradeoff they made.
No duplication of data, and that’s why this is such an amazing design.
Query Path
Like, let’s say, I want to search for the following —
/SEARCH - “hello server” mentions: “sahil” attachment_extension: .pdf in:#backend-channel
Let’s understand what the above query means.
Give me all the messages from the guild #backend-channel with message as “hello server”, which mentions the user “sahil”, and which contains a .pdf file.
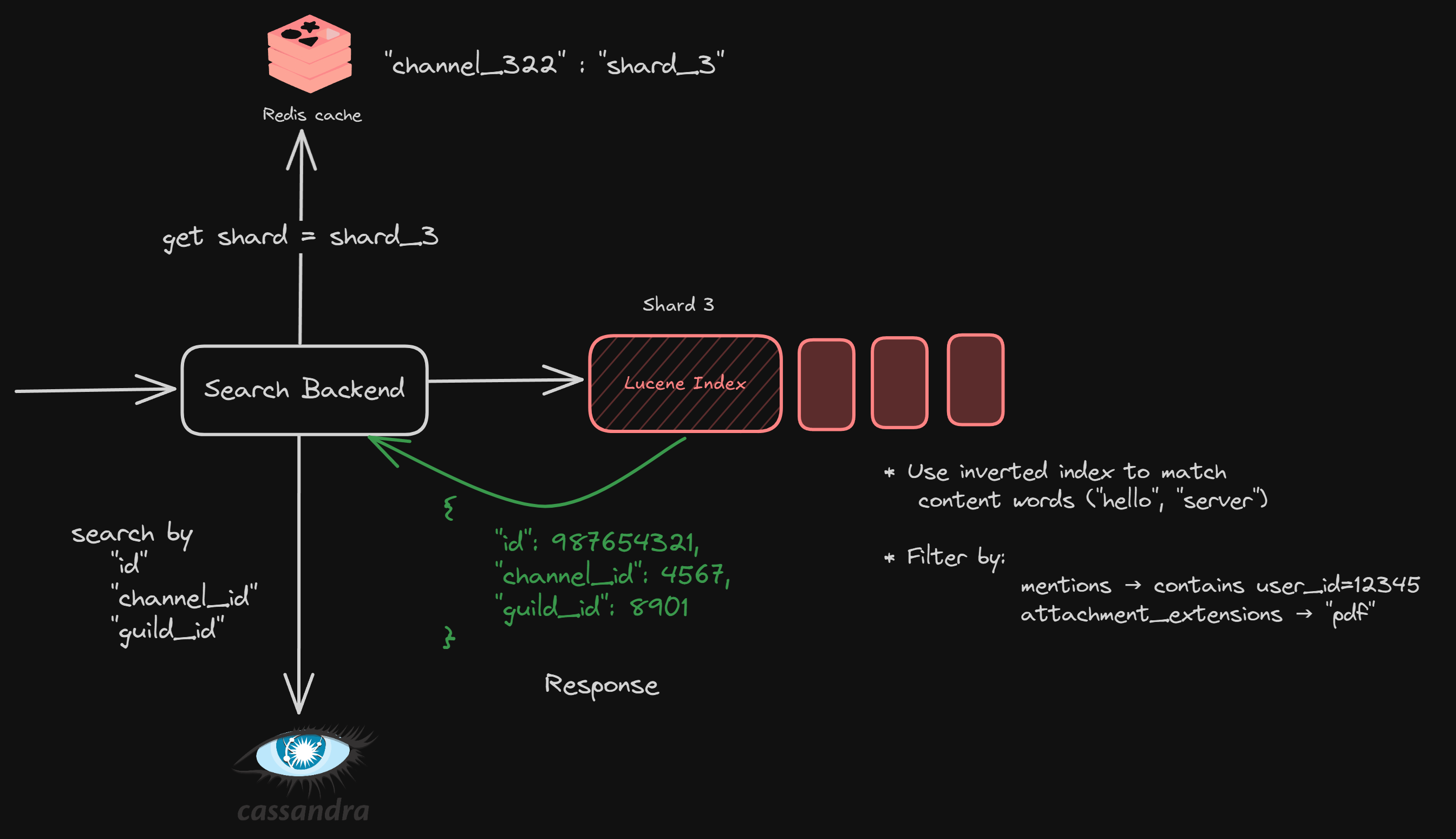
Elastic always returns only the “id”, “channel_id”, and “guild_id” for every search. And it’s Cassandra’s responsibility to get the context (2 messages before and after) to power the UI.
Challenges
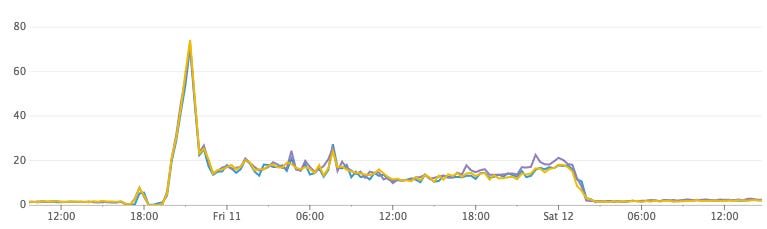
When they were testing this in production, they found that CPU usage was way higher than expected. Also, the disk usage was growing way too fast for the volume of messages being indexed.
{kind=link}
{kind=link}
They cancelled the index jobs after a few hours and left them overnight. When they came back, they saw that the CPU usage had dropped significantly.
After doing some research, they found out that by default, Elasticsearch has its index refresh interval set to 1 second.
This is what provides the “near real-time” search ability in Elasticsearch. Every second (across a thousand indexes), Elasticsearch was flushing the in-memory buffer to a Lucene segment and opening the segment to make it searchable.
So they tuned this interval to 1 hour, but that would mean all the results are only searchable after 1 hour. We need to make sure we don’t show stale/incorrect search results.
So, they did the following —
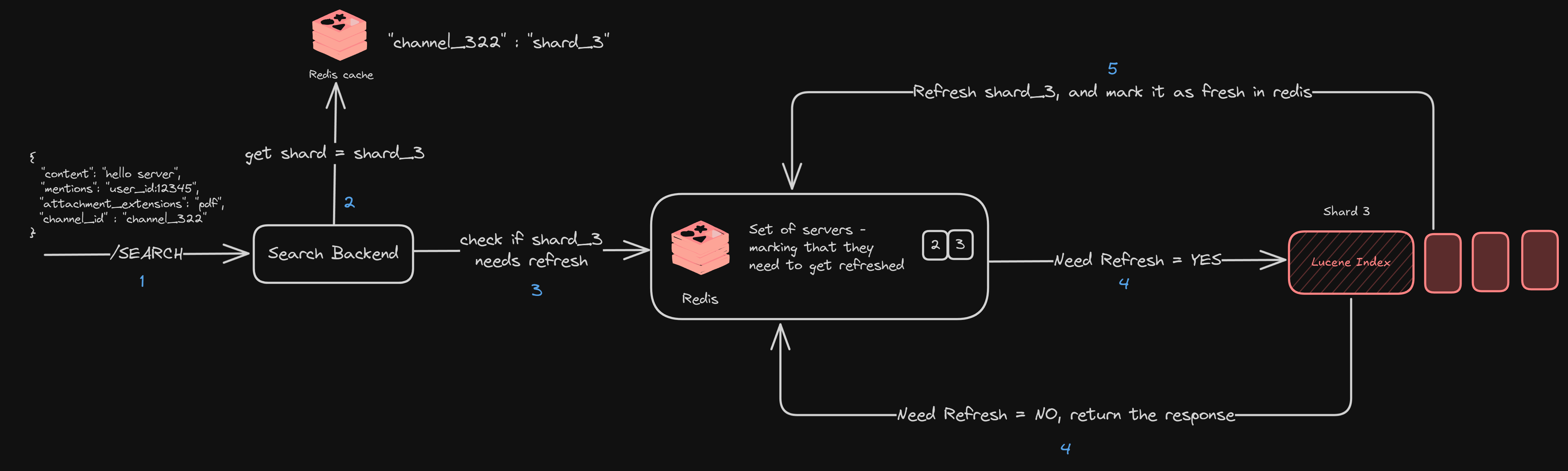
Kept a mapping of servers that “required refresh” when new messages are ingested into them
When searching those servers, if they were marked as “required refresh”, they refreshed them and returned the result. (also marking them as fresh)
I believe that studying this design is one of the best ways to understand how to design a feature, considering the constraints.
Discord not only designed an amazing search system, but the way they designed it, the decisions they made to optimize for the constraints while not compromising any of the requirements, is just amazing.
Wrapping Up
What I really like about this system is how brutally practical it is.
They didn’t try to build the most elegant, real-time, shiny search system. They built something that works, and works well at Discord scale, without burning a hole in their infra budget.
App-layer routing? Lazy indexing? Just storing metadata?
All of that screams one thing: we shouldn’t solve more than we need to.
But whatever we do solve, we should make sure it doesn’t break under pressure.
The system doesn’t aim for perfection. It aims for survival. And that’s the kind of thinking I’ve started to respect more and more.
Because let’s be real, most things in prod break. The question is: can they recover without waking you up at 2 AM?
That’s all for this one. Next month, we will break something else.
Stay tuned!
References
I highly suggest to read the original Discord blog, its perfect, doesn’t put a lot of jargons, and its flow is amazing. A great piece of writing.
https://www.hellointerview.com/learn/system-design/deep-dives/elasticsearch
https://www.elastic.co/blog/found-elasticsearch-from-the-bottom-up
Last month, I put out a Google Form for feedback on Breaking Prod. I didn’t get any response. I guess I was expecting that.
So, no form this time. If you felt this was helpful, reply back, comment, or DM.
The merging of segment that you are saying is probably segment compaction process that is done similar to LSM tree databases.
Hi sahil, I don't think making any design decision (like elasticsearch here) can be based on if engineers know about it. Ideally one should focus on the tradeoffs and ways to tackle issues which can occur in long term usage (issue that occur when system scales/ goes down ) before selecting anything