

Webhooks — The Push-Based Design Behind Async Communication
How systems like Stripe notify clients reliably across distributed boundaries

This will be the start of a 3-part series on systems that seem familiar, which can be used interchangeably, but are quite different in how they are fundamentally designed.
For today’s post, we will look at Webhooks.
Let’s try to understand WHAT they are, and WHY we need them.
How to get updates from an async process?
Let’s consider a scenario, and I believe it might be a common one.
You are working on your new app, and you want to integrate payments into it. So, you use Stripe for payments.
Every time a user wants to pay, you call a Stripe API, and it returns a result as a confirmation of the payment, if it suceeded or failed.
Now, to truly understand what webhooks are, let’s forget about Stripe for now. Let’s assume we are building something like Stripe, and let’s look at a problem that our client might face while calling our gateway.
Especially, as the title suggests — “how to get updates from an async process?”
Consider the design below —
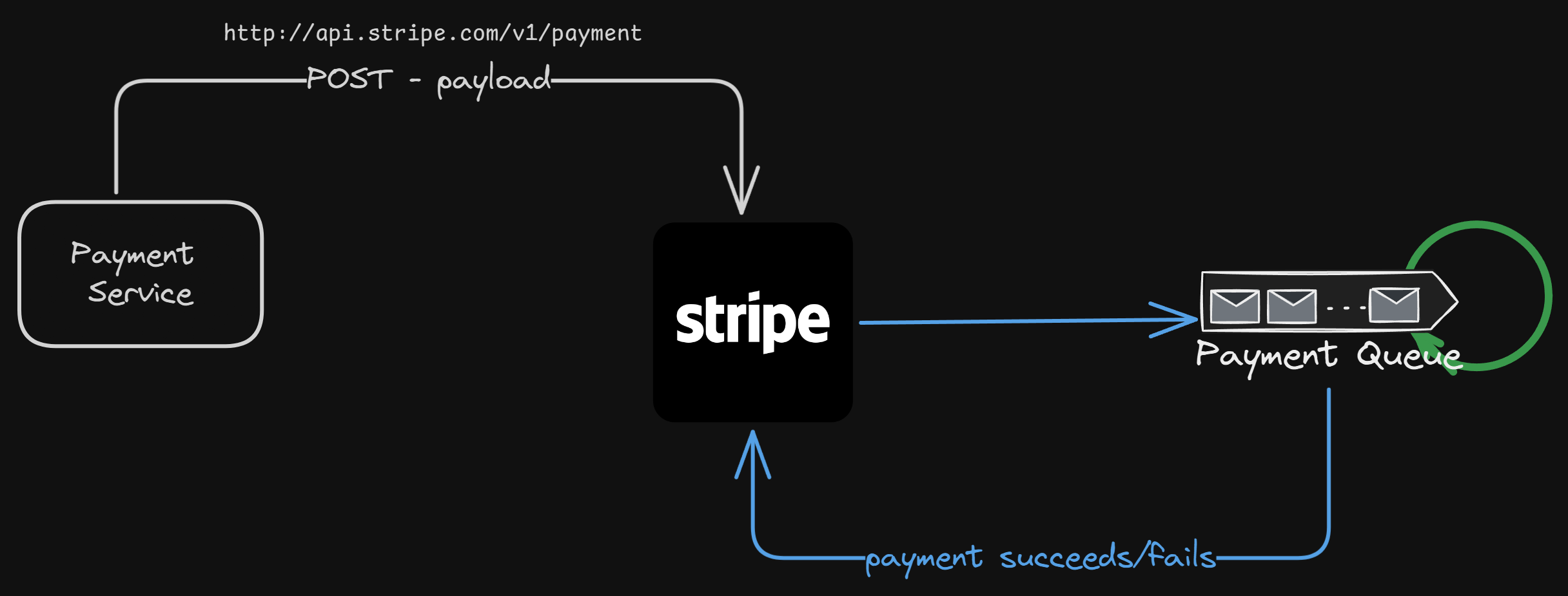
Here are the steps that might happen —
Our
PaymentServicecalls a Stripe endpoint with the necessary information for payment.Now, Stripe on their end might have some queue for all the payment requests that they get, and they process them asynchronously (we will get in deep into this later in this article).
Now, the payment is processed, and we want the result from Stripe. What do we do?
Let’s look at a couple of different ways of getting the information from an external vendor, like Stripe (for an async request).
Pull-Based Approach
If Stripe has that information, then maybe our PaymentService can call Stripe’s API to get the latest information on whether that request is completed or not.
We can keep an exponential retry on a request, and keep calling Stripe until we get a confirmation from them that a payment is completed.
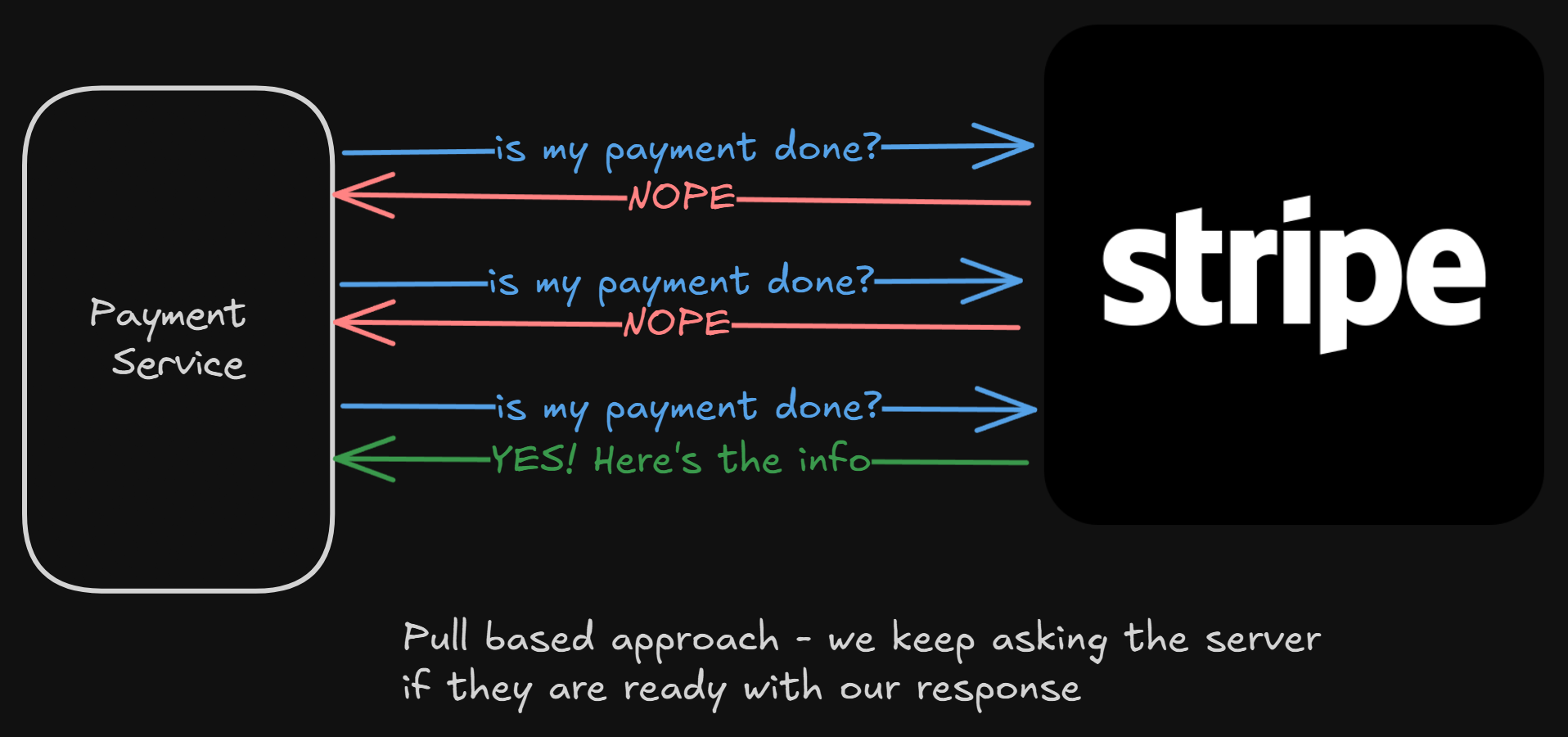
But I think it consumes a lot of resources. Every few seconds, our service has to make an external call, wait for their response, and the response can’t even be valuable.
On the other hand, Stripe’s API will probably get flooded with so many requests from their clients, asking them the information for their payment.
It’s not scalable in this case.
Push-Based Approach
Instead of PaymentService calling Stripe again and again to check the status, what if it does the following —
Tell Stripe — “whenever you are ready with my payment request, just let me know”
Now, Stripe can process the payment async, and whenever it’s done, it can call our PaymentService, telling us the details of the payment
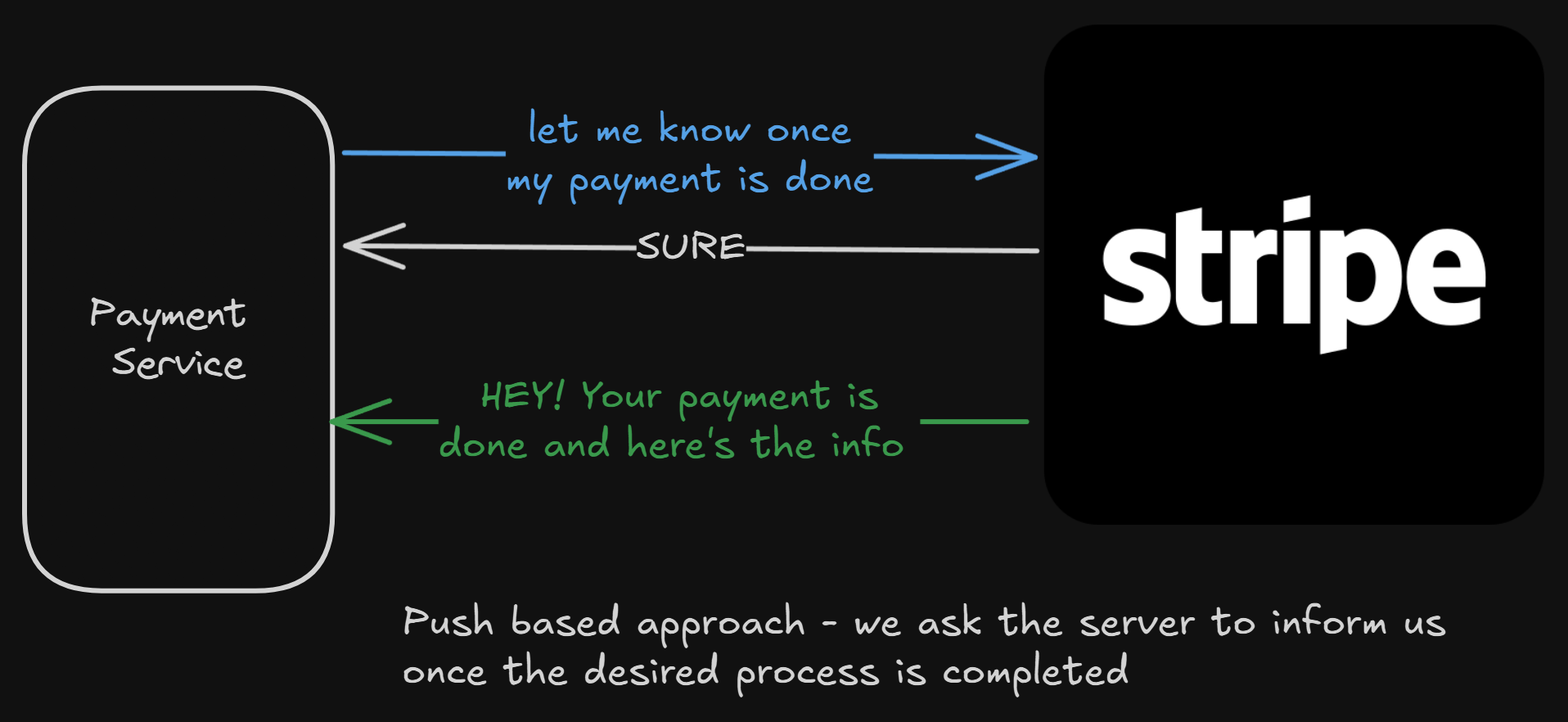
This is clean. None of the servers is loaded with frequent status check calls.
How do we do something like this?
Well, that’s exactly what we are looking at today.
Building Webhooks
But achieving something, at the scale of Stripe, is a different thing altogether. There are a lot of moving parts that need to be handled when designing a webhook-based system that works on a global scale.
But let’s think about it, one system at a time.
Client registering the webhook call
That’s the first step.
Let’s say we have an endpoint — https://api.stripe.com/v1/payment
And we have asked our clients to do a POST call on this endpoint with some parameters. Let’s look at what those parameters could be —
Payment info (amount to charge and a few other details)
Client ID (to specify which client wants to get notified after the event)
Callback URL (which endpoint should Stripe call once the payment is done)
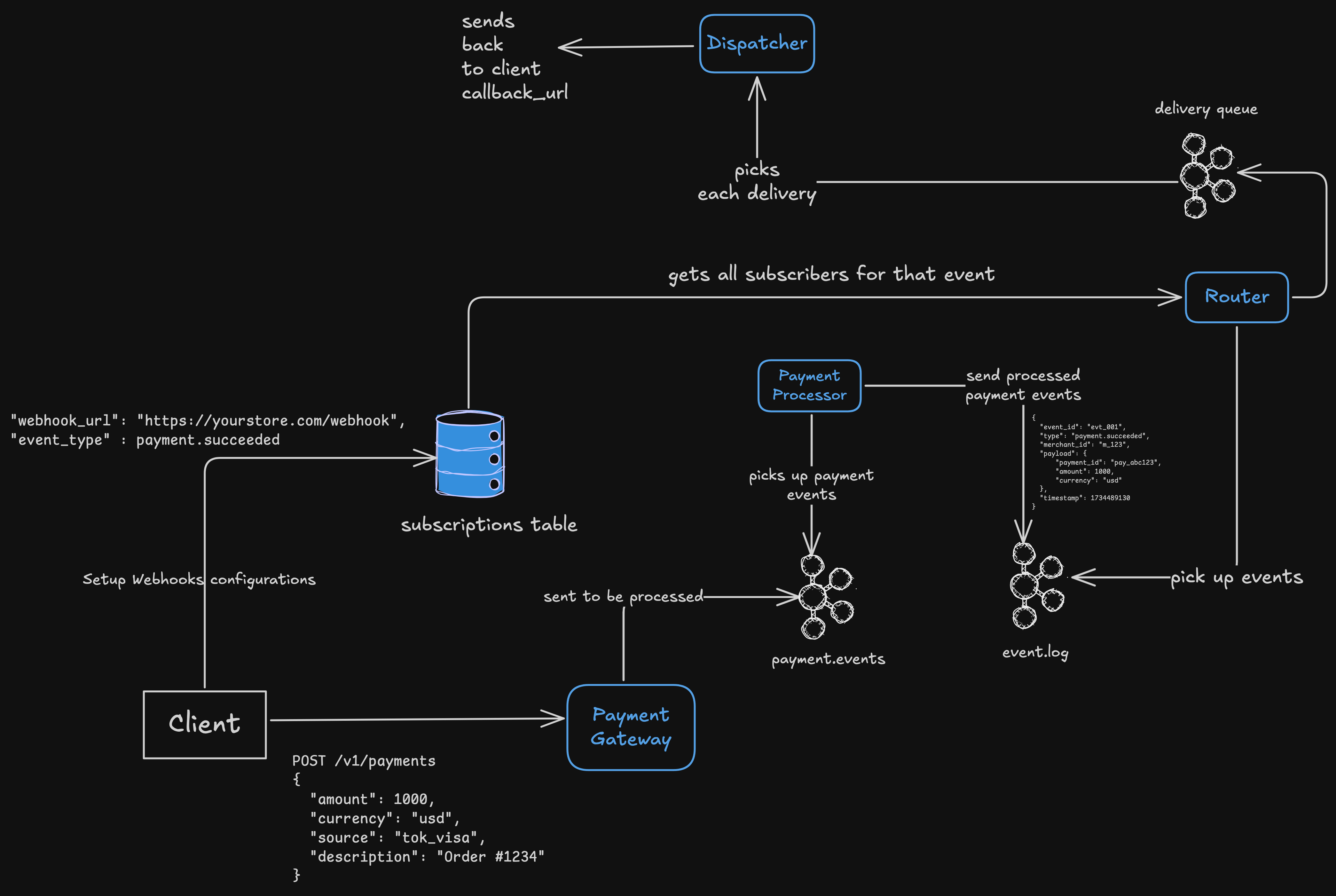
Ingress
Everything begins here. The core product (like Stripe Payments) emits internal events to a shared message bus, typically Kafka or a message queue.
There are a few properties of this:
Each event = small object (
event_id,type,payload,timestamp).Stored in a topic partitioned by tenant or event type.
Ordered delivery per tenant (e.g., all events for one customer go to the same partition).
Payment service
├─→ Kafka topic: payments.events
│ - key: merchant_id
│ - value: {”type”: “payment.succeeded”, ...}
├─→ Kafka topic: user.events
│ - key: merchant_id
│ - value: {”type”: “user.created”, ...}Event router/subscription service
Now, we need some kind of way to find who to notify about an event. And that’s what we do here.
Every merchant registers their callback_url and their event_type And that’s what we store here in this DB.
merchant_id | event_type | callback_url | secret | status
----------------------------------------------------------------
m_123 | payment.succeeded | https://storeA.com/webhook | ... active
m_124 | * | https://storeB.com/hook | ... activeWhen the router consumes from the event bus:
It looks up all subscribers for that event type.
Enqueues one “delivery job” per subscriber, some kind of a delivery queue.
The delivery queue (Kafka) can now fan out across multiple subscribers; it decouples event generation from delivery.
So, in this way, one payment success event could become 10 delivery jobs (if 10 subscribers exist).
[Event Router] consumes Kafka topic → writes to Delivery Queue
Event {type: payment.succeeded, merchant: m_123}
⤷ Delivery Job 1 (m_123, https://a.com)
⤷ Delivery Job 2 (m_999, https://b.com)Dispatcher workers (the delivery layer)
This layer is the one that makes sure that the process status is sent back to the webhook clients.
Each worker process:
Pulls jobs from the delivery queue.
Sends the event via HTTP POST.
Records result (success, failure, latency).
Retries failed jobs with exponential backoff
DispatcherWorker:
1. job ← queue.pop()
2. payload ← fetch(event_id)
3. headers ← build_signature_headers(payload, secret)
4. resp ← http.post(callback_url, json=payload, headers=headers, timeout=5s)
5. if success: mark_delivered()
else: enqueue_retry(job)
Retries
But we can’t just retry a failed job blindly. If we do so, we might DDoS ourselves. We need to design the retry carefully.
So we can maybe separate the main queue and retry queue, with different timeouts.
We can do something like this —
Retry #1 → after 1 min
Retry #2 → after 5 min
Retry #3 → after 15 min
Retry #4 → after 1 hr
Max retries → 24 hr, then dead-letter queue.
So, let’s look at how we have designed it till now.
Something to Note
The whole design relies on event driven system, and when we are in a world of distributed systems and queues, we are dealing with at least once semantics. And for that, we need to handle idempotency at the consumer level.
The last few of my posts deal with idempotent systems. You can take a look at these posts for reference —


Back-pressure and blocked consumer problem
If one of the consumers is slow, i.e., if its callback endpoint is slow, it could block our whole pipeline, and the dispatcher would keep retrying.
What to do to handle this? We can’t let one blocked consumer block our entire flow.
Let’s look at a few of the options we have —
Tenant Sharding
We can partition the delivery queue by tenant or region. Something like this —
delivery_queue_m123
delivery_queue_m124
...Each worker pool processes a subset of these tenants; this prevents one slow customer from affecting others.
Rate limits per client
We can apply a configurable delivery concurrency per tenant (something like 5 in-flight requests max at a time).
Circuit breakers
If a tenant’s endpoint fails N times in a row, we can pause deliveries for that tenant for a cooldown period (it can be configured per tenant).
Design
This design captures the tradeoff between a huge number of events and delivery fairness.
A monolithic system with a “just-send-HTTP” approach will collapse under backpressure, retries, and latency spikes.
What Stripe, GitHub, etc. have done is essentially build a mini pub/sub system on top of HTTP, with —
Persistent queues
Isolation boundaries
Delivery semantics
That’s what makes it production-grade.
Looking Back…
At the surface, a webhook feels simple — one service calling another.
But underneath, it’s a quiet agreement between systems: “When something happens, I’ll tell you.”
It’s trust, made machine-readable.
Retries, backoffs, and queues aren’t just technical constructs — they’re the system’s way of keeping its promise even when the world can break apart.
That’s what makes distributed systems so human sometimes, it’s that everything is asynchronous, everything can fail, and yet we keep finding ways to communicate, to notify, to stay consistent in the face of uncertainty.
In the next part, we’ll look at a different kind of communication — one where the connection never really closes: Server-Sent Events (SSE).
A Message
I’ve been thinking a lot about how writers monetize their content in different ways, including paywalls. That’s not what I want for this space.
Everything I write here will stay free; that’s important to me. At the same time, writing takes time, solitude, and energy.
If you have ever felt that my work helped you in some way, and you want to support it, you can do that here —
++ Good Post, Also, start here how to build tech, Crash Courses, 100+ Most Asked ML System Design Case Studies and LLM System Design
How to Build Tech
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-10-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-06-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-05-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-04-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-03-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-01-the-heart-of?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/howtobuildtech/p/how-to-build-tech-02-how-to-actually?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
Crash Courses
https://open.substack.com/pub/crashcourses/p/crash-course-09-part-1-hands-on-crash?utm_campaign=post-expanded-share&utm_medium=web
https://open.substack.com/pub/crashcourses/p/crash-course-07-hands-on-crash-course?utm_campaign=post-expanded-share&utm_medium=web
https://open.substack.com/pub/crashcourses/p/crash-course-06-part-2-hands-on-crash?utm_campaign=post-expanded-share&utm_medium=web
https://open.substack.com/pub/crashcourses/p/crash-course-04-hands-on-crash-course?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/crashcourses/p/crash-course-03-hands-on-crash-course?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/crashcourses/p/crash-course-02-a-complete-crash?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/crashcourses/p/crash-course-01-a-complete-crash?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
LLM System Design
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-577?utm_campaign=post-expanded-share&utm_medium=web
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-4ea?utm_campaign=post-expanded-share&utm_medium=web
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-499?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-63c?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-bdd?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-661?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-83b?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-799?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-612?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-7e6?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-67d?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/most-important-llm-system-design-b31?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://naina0405.substack.com/p/launching-llm-system-design-large?r=14q3sp
https://naina0405.substack.com/p/launching-llm-system-design-2-large?r=14q3sp
[https://open.substack.com/pub/naina0405/p/llm-system-design-3-large-language?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/important-llm-system-design-4-heart?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false
https://open.substack.com/pub/naina0405/p/very-important-llm-system-design-63c?r=14q3sp&utm_campaign=post&utm_medium=web&showWelcomeOnShare=false