


We saw earlier that SQL can be distributed (see CockroachDB). But if multiple servers are in different places, how will you achieve one of the most important features of databases: transactions?
Normal Transactions
Let’s look at what transactions are.
BEGIN TXN
DEDUCT 1000 FROM BANK ACCOUNT NO. 123
ADD 1000 IN BANK ACCOUNT NO. 456
END TXNThis is what a txn is. It contains some operations that, if any of them fails, all the operations that were a part of that txn are reverted to the original state.
It makes sense; if an amount was deducted from your account but didn’t reach the other account, you should get the money back!
When we have a single database server, it’s all good because network failures don’t affect it if the servers are not distributed (Remember the CAP theorem?).
Distributed Transactions
But what happens if my database is distributed and the client executing the txn was connected to server1, but server1 cI rashed in between my txn. Where will my money go?
To tackle this specific problem, there are multiple amazing methods to ensure we achieve distributed transaction.
Two/Three-Phase Commit (2PC/3PC)
How It Works
Prepare Phase:
The coordinator asks all participants (nodes) if they can commit.
Each participant writes the transaction to a log (WAL) but has not committed yet.
If a participant fails, the transaction is aborted.
Commit Phase:
If all participants agree, the coordinator sends a commit message.
Each participant then commits the transaction.
If any participant fails, a rollback is triggered.
Problem
Blocking: If the coordinator crashes after "Prepare," participants are stuck.
Single Point of Failure: If the coordinator crashes, the system stalls.
Due to the limitations of 2PC, consensus algorithms like Paxos were developed to handle failures more gracefully.
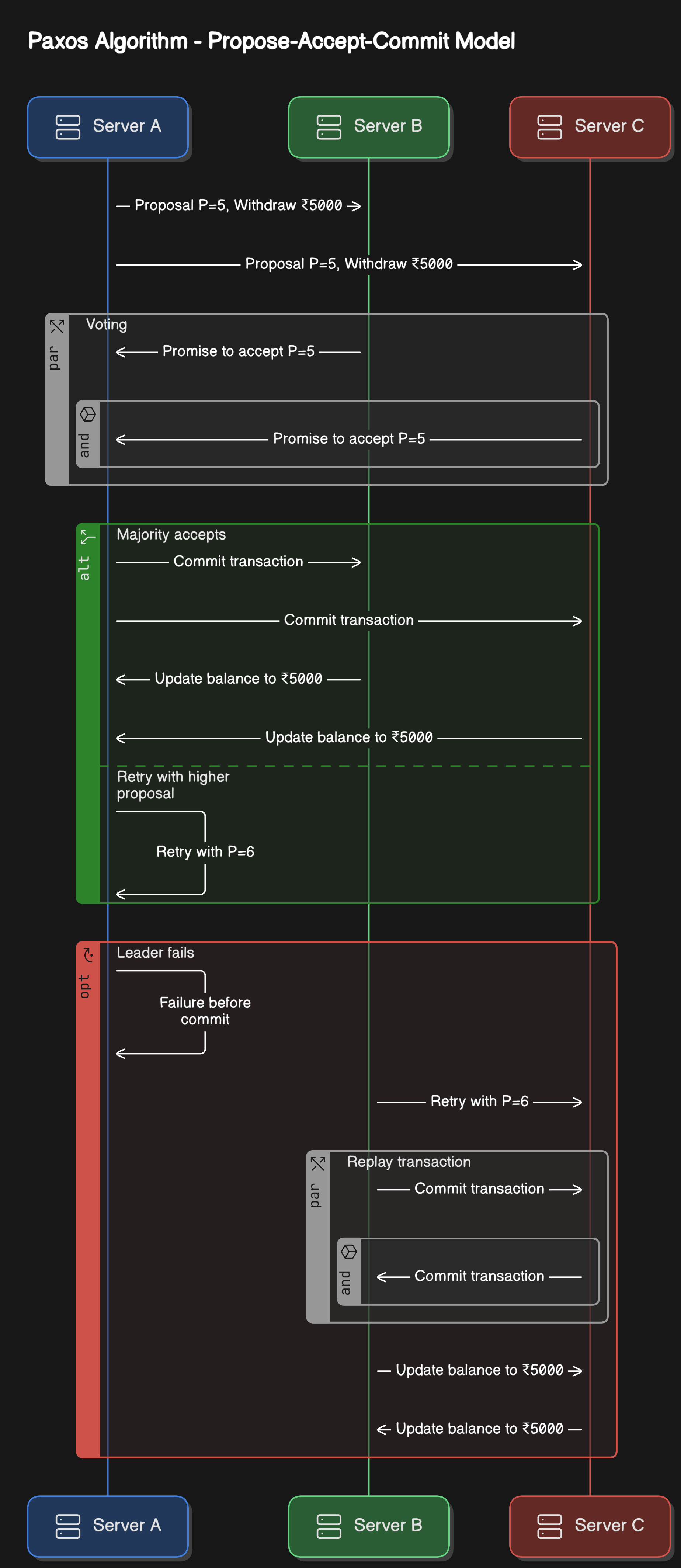
Paxos Algorithm
It allows a group of nodes to agree on a value (e.g., a transaction) even if some nodes fail. Paxos follows a Propose-Accept-Commit model. Let’s understand this algorithm with an example.
Imagine we have a banking system running on 3 servers:
Server A (Mumbai)
Server B (Bangalore)
Server C (Delhi)
A customer, Adam, has ₹10,000 in his account. He initiates a ₹5,000 withdrawal.
The problem with distributed transaction
If Adam’s transaction is processed on Server A, but Server A crashes before updating other servers, the system will be inconsistent. Servers B and C might still think the customer has ₹10,000.
Step 1 - Proposer (Leader) Sends a Proposal
Server A (Leader) picks a proposal number (say P=5) and asks Server B and Server C if they are willing to accept it.
Example: "Proposal P=5, Withdraw ₹5000 from Adam’s account"
Step 2 - Acceptors Vote
If Server B and C have not seen a higher proposal number, they accept P=5.
Otherwise, it rejects the proposal (if a higher one exists).
They will reply - “Promise to accept P=5, will not accept lower proposals”
Step 3 - Commit or Retry
Since a majority (2 out of 3 servers) accept P=5, Server A commits the transaction and tells others to finalize it.
The servers updated Adam’s balance to ₹5000.
If not, the proposer retries with a higher proposal number.
What If the Leader Fails?
If Server A fails before commitment, another server (B) retries with a new proposal P=6.
Since a majority (B and C) already agreed on a ₹5000 withdrawal, they will replay the transaction and commit it again.
This ensures the transaction is never lost
Limitations of Paxos
Complex to implement.
Slow because it requires multiple network round-trips.
Not optimized for fast leader election.
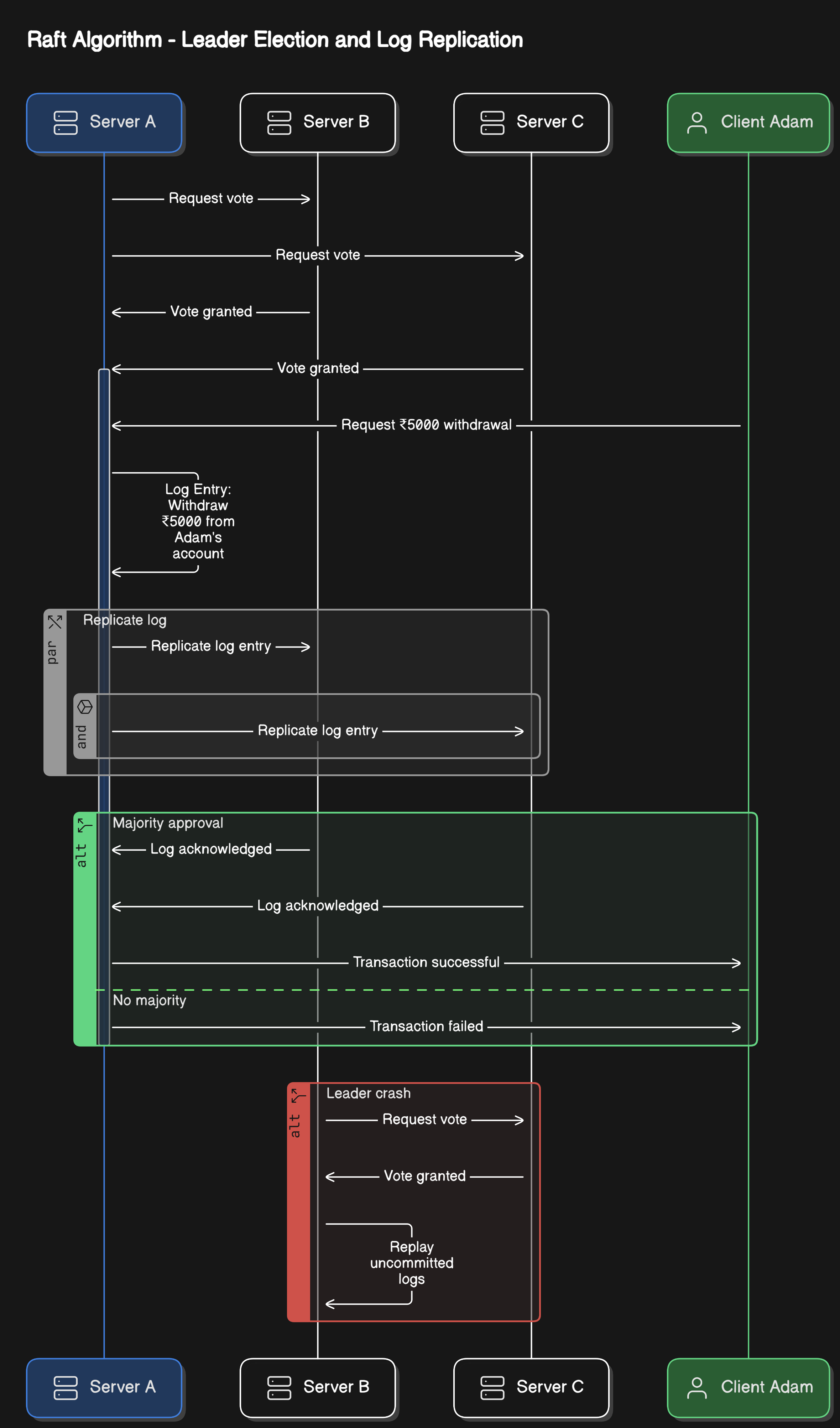
Raft Algorithm
Raft simplifies consensus by electing a leader to manage transactions. We will examine the same example above.
Step 1 - Leader Election
Initially, no leader exists.
Servers vote for a leader. If Server A gets a majority vote, it becomes the leader.
Leader A now controls transaction commits.
Step 2 - Log Replication
Adam requests a ₹5000 withdrawal from Server A (Leader).
Server A logs the transaction and sends it to B and C.
The server will log something like - “
Withdraw ₹5000 from Adam's account”
Step 3: Commit with Majority Approval
If a majority (B and C) acknowledges the log, the transaction is committed.
Leader A tells all followers to update the database.
Step 4: Handling Leader Crash
If Server A crashes, a new leader (Server B) is elected.
B replays uncommitted logs and continues execution.
Key Differences
Paxos allows any node to propose a transaction
Raft has a single leader that manages transactions
Google Spanner uses the Paxos algorithm
Etcd, Consul, CockroachDB uses Raft Algorithms
Conclusion
Ensuring transactions in distributed databases is challenging but achievable with 2PC/3PC, Paxos, and Raft. While 2PC is simple, it suffers from blocking issues. Paxos ensures consensus but is complex, whereas Raft simplifies leader-based replication.
That’s it for this week. Will be back next week with something interesting.
Great article. These topics got refreshed for me.