

Gossip In Distributed Systems
How human behaviors shaped a key concept distributed systems

I have been working on my key-value distributed database in my free time. To make it truly distributed, I looked into different ways where multiple servers interact, how the topology affects these, and the efficient approaches other databases take in this.
I found that this topic is called Gossip. It is based on the fact that humans spread information among themselves (by gossiping).
Let’s look at these algorithms in detail.
Gossip
Let’s define it first -
Gossip protocols are a method of communication in distributed systems where nodes exchange information by periodically selecting random peers and sharing updates.
Suppose we have the following topology of all the servers in a network. Maybe this is not an accurate description, but it can suffice the point I will make.
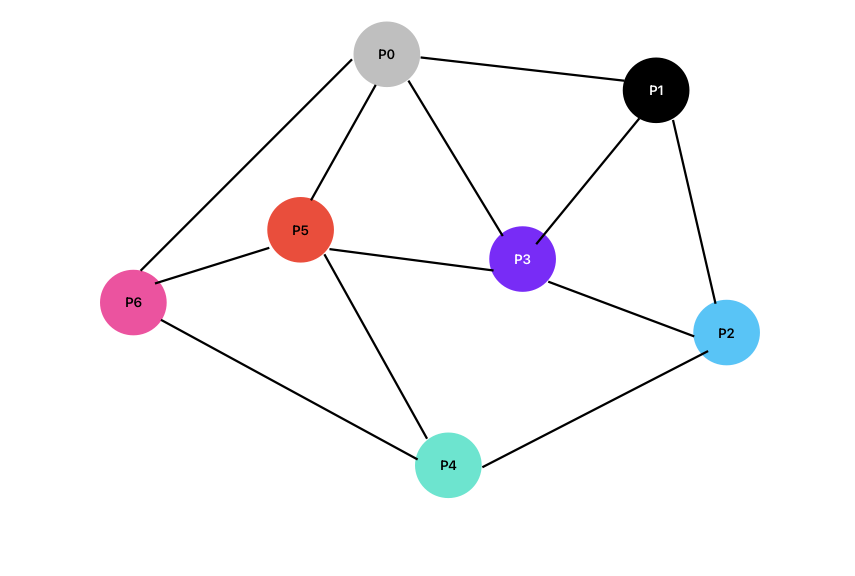
In large distributed systems, ensuring that all nodes receive updates quickly and efficiently is challenging. Traditional client-server models create bottlenecks.
How will you decide which ones to send the information to? How can you make sure you get an accurate idea about all the servers in the network?
Let's look at P0 in the network above. We will have to check which nodes are unhealthy so we can replace them.
P0 sends health checks to P6, P5, P3 and P1. P6, P5 doesn’t send ACK back, meaning there might be some issue in the network.
Let’s list down the possible causes by which this can happen -
Network partition between P0 and (P1, P6, P5)
Some issue in P1, P6, P5
Some issue in P0 itself while getting the ACK back
So, doing just 1 health check to neighboring nodes doesn’t guarantee a status check to those nodes.
Let’s look at it another way. What if we send a health check to all the nodes in the network from P0? It makes sense, but it’s not scalable when we are dealing with thousands of nodes in the network across the globe.
We want some kind of consensus to help us be sure that exactly those nodes are affected.
How to Gossip Efficiently
How can we improve the algorithm we saw above? Let’s modify it slightly.
Every node in the system periodically picks a random peer and shares information with it.
This process continues, ensuring that information spreads exponentially
Gossip protocols do not guarantee immediate consistency but achieve eventual consistency (as it takes time for information to reach all the nodes this way)
The speed of information propagation is measured using the epidemic threshold (as in the rate at which an epidemic spreads), determining when most nodes have received the data.
Advantages
Decentralized – No single point of failure; all nodes participate equally.
Fault-Tolerant – If some nodes fail, the protocol still works as long as enough nodes remain functional.
Scalable – Works well even in large distributed networks with thousands of nodes.
Low Overhead – Communication cost is minimal compared to broadcasting to all nodes.
Types of Gossip Algorithms
There are different types of gossip protocols depending on their purpose:
A. Epidemic Dissemination (Data Propagation)
Used for spreading updates efficiently across a network.
Works similarly to how a virus spreads in a population.
Example: DynamoDB propagates data updates via gossip.
B. Failure Detection (Gossip-Based Heartbeating)
Nodes gossip about their health and the health of others.
If a node stops responding for a certain number of rounds, it is marked as failed.
Example: SWIM (Scalable Weakly-consistent Infection-style Membership) protocol used in HashiCorp Serf and Consul.
C. Membership Management
Nodes gossip to exchange lists of known peers, maintaining an up-to-date view of the network.
Example: Kubernetes uses gossip to manage dynamic cluster membership.
D. Aggregate Computation
Nodes use gossip to compute network-wide statistics like average CPU usage, total storage, etc.
Example: Google Borg uses gossip to monitor resource usage across data centers.
How Gossip Works
Let’s look at the same example we saw earlier about the nodes. Now, while gossiping, the information “Upd” will be transmitted the following way -
Round 1 - P0 randomly selects P1 and sends the update (marked in “blue”)
Round 2 - Now, since P0 and P1 both have “upd”, they both will pick other nodes randomly (here, P0 picks P4 and P1 picks P2, marked as “purple”)
Round 3 - Now, P0, P1, P4 and P2 all have “upd”; all of them will randomly pick other nodes (marked as “green”)
This will go on until all the nodes have the update.
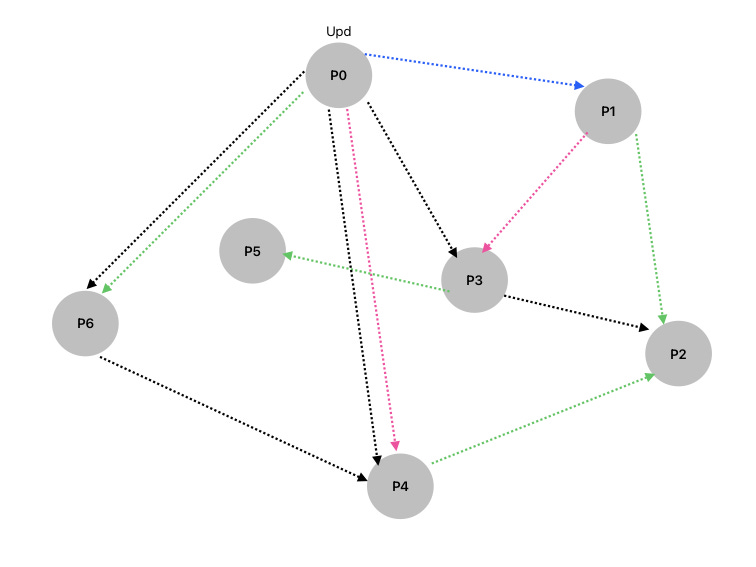
This raised a question: How do nodes know when to stop? We can see in the “black” that in Round 4, there are nodes that already have the update “upd”, but they still get the message.
There are multiple methods to make sure the gossiping ends -
1. Epidemic Threshold (Probabilistic Stopping)
Gossip protocols usually assume that after log(N) to O(N log N) rounds, nearly all nodes will have received the message.
Instead of running forever, nodes stop gossiping when they haven't received any new updates for a predefined number of rounds.
2. Push-Pull Model
Some gossip protocols use a push-pull strategy where nodes not only send updates but also request them from peers.
If a node detects that it is receiving the same update multiple times, it can stop propagating further.
3. TTL (Time-To-Live) or Gossip Count
Each message may contain a TTL value or a counter (e.g., max hops = log(N)).
Nodes decrement this value every time they forward the message, and when it reaches zero, they stop.
4. Convergence Detection
Nodes can track how often they receive duplicate messages.
If a node sees the same message k times without new information, it assumes that the network has converged and stops gossiping.
Now that we know all these, let’s look at the pros and cons of gossiping.
Advantages & Trade-offs
Advantages
Scalability – It works well even for large-scale distributed systems.
Fault Tolerance – No central dependency; even if nodes fail, the system continues.
Resiliency to Network Partitions – Since gossip works in a peer-to-peer fashion, updates can reach disconnected nodes when the partition heals.
Trade-offs
Redundant Messages – Nodes might receive the same message multiple times, increasing bandwidth usage.
No Strong Consistency – Data synchronization takes time, leading to eventual but not immediate consistency.
Latency Variability – Some nodes may receive updates much later than others.
Let’s Conclude
Gossip protocols are lightweight, scalable, and fault-tolerant, making them ideal for large distributed systems.
They provide eventual consistency and can be used for data propagation, failure detection, and distributed coordination.
Future improvements can focus on reducing redundancy, improving efficiency, and adding security measures.
It will be a fun challenge to implement all these gossip algorithms and stopping conditions worth a try.
That’s all for this week, I will come back with something more interesting (hopefully).