

How gRPC works: Rebuilding gRPC from First Principles
A deep dive into the design, internals, and real-world performance of modern RPC systems


In the last post, we saw that a normal REST call is based upon the HTTP/1 protocol. We also saw HOW HTTP/2 builds on the limitations of HTTP/1, which gRPC utilises amazingly.
In this post, let’s look more deeply at HOW gRPC works, and WHY it’s fast, more efficient than traditional REST.
This is part 2 of the gRPC series. I highly suggest you read the previous post, to fully grasp the need for gRPC, and how it fits right along with HTTP/2.
Problems with REST
REST works, and it’s working now, and it will work for a long time in the future.
It’s great when we want to communicate in a human-readable format. But once we get to scale, real-time performance, and live streaming, it starts slowing down.
JSON is bulky, slow to parse, and wastes bandwidth.
No structure: No contracts. Clients and servers can do entirely different things, without anyone knowing about the other.
No streaming: We take different routes with long polling or WebSockets
Manual everything: Timeouts, retries, error handling, all done manually.
When HTTP/2 came, we needed something better than REST, that takes all the beautiful things REST does, but in a more compact, efficient way.
That’s where RPC came in.
RPC (Remote Procedure Call)
When we look at the definition of RPC, we get this idea —
Calling another function remotely like its a native function
But how is that possible?
Consider this scenario.
You are a client, and you want to filter all the users by their last name.
Normally, you would do a /GET call to your API, with some filters, maybe — GET /user?last_name=sarwar.
But what RPC says is, all you need to do is the following —
filteredUsers = service.GetUser(FilterRequest{LastName: "Sarwar"})And that’s it. No API call (at least, not the one we can see directly), no JSON parsing, nothing. Just a native function call.
How is that possible? Obviously, we are surely making a request to the server somehow, but it’s hidden in a way.
Let’s see what’s going on underneath.
How do we call a function on another machine?
HOW will we call a function on another machine, without the normal REST call?
All I can think of is that, since we can’t use REST, we need to modify the way data is transferred over HTTP itself, maybe something more compact, something structured.
We also need some kind of way to parse and map the data transferred over the network to the functions (endpoints) on the server side.
Like, in a naive way, something like this —
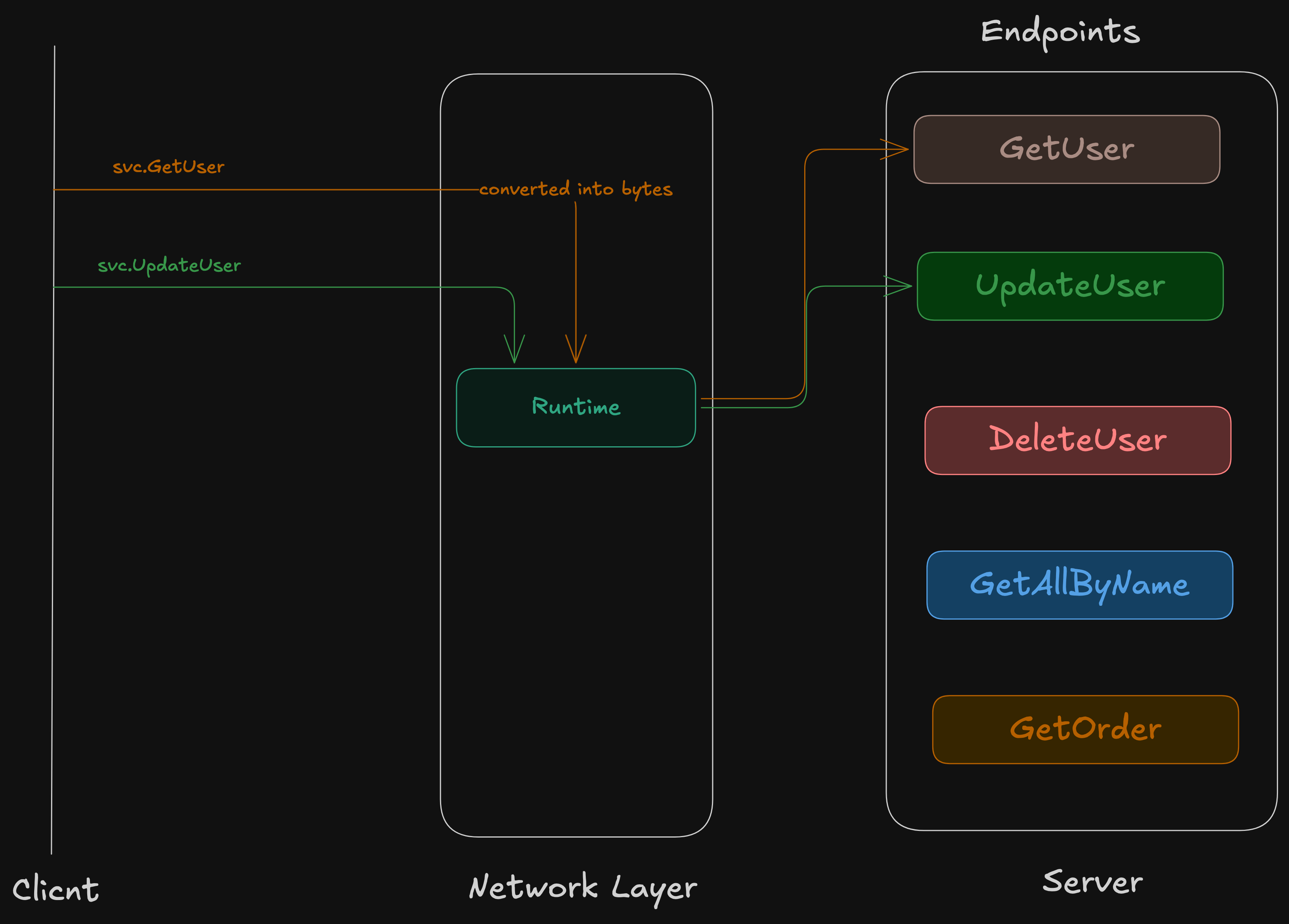
Please note, this is not how it actually works; it’s just a naive design on how I would approach designing it.
So, we need some mapping between the client calling a native function to the data transferred and the corresponding server endpoints.
Turns out, that’s the whole point. If we successfully parse the data being transferred and map it, we’ve built a basic version of RPC.
Rebuilding an HTTP Request
So, we saw that we need to redesign how we send data, how we parse data over the network.
To rebuild an HTTP Request, we need to look at how they are done in a basic REST protocol.
The request body is usually sent as JSON.
The response can be JSON, HTML, XML, or anything else, depending on
Acceptheaders.The API endpoint (
/user,/order) defines what we’re calling.The HTTP method (GET, POST, PUT, DELETE) tells us what kind of action this is.
But now, since we’re not using REST, we don’t have any of that.
There’s no method type, no path, no JSON. So the big question becomes —
How do we encode the same instructions, the operation, the arguments, and the expected response in a raw network payload?
We’ll need some way to:
Define which function to call (like
/user).Pass structured input data (like user filters).
Parse the response in a format the machine can understand.
That’s where ideas like Protobuf, service definitions, and binary encoding come in; they’re not magic, they’re just solving these exact problems.
Protocol Buffers
As we saw above, we need to put all the information that REST provides into something more compact and structured.
That’s where Protocol Buffers, or Protobuf, come in. It’s like a contract between the client and server —
What functions exist
What inputs do they expect
What output will they return
It’s actually a structured language, with its own separate syntax, so it’s encoded/decoded in a binary format.
Let’s see how Protobuf solves the problems we asked about above.
Which function to call?
In REST, it’s usually a path like — GET /user?last_name=sarwar
In protobuf, we define it as a service and a method name.
service UserService {
rpc GetUser(GetUserRequest) returns (User);
}There is no /path, no HTTP methods, just a function name GetUser, inside a service called UserService. That’s the endpoint.
How to send structured data?
REST uses query parameters and JSON as the body.
gRPC (with Protobuf) uses a strictly defined message, like —
message GetUserRequest {
int32 id = 1;
string last_name = 2;
}This gets serialized into binary, not JSON, which means it's compact, fast, and easier to parse both on the client and server side.
How to parse the response?
In REST, we get different outputs according to our Accept headers, like HTTP, JSON, XML, etc.
In gRPC, we will have to define the response, just as we defined the request —
message User {
int32 id = 1;
string name = 2;
}So when the server responds, we already know exactly what fields to expect and in what format.
To know more about the syntax of gRPC.
But wait, how do we know which endpoint to call?
Cause eventually the endpoint, which we call in REST, would be something like - https://www.api.example.com/users?last_name=sarwar
We do this while we are setting up the gRPC service.
conn, err := grpc.Dial("api.example.com:50051", grpc.WithInsecure())
if err != nil {
return err
}
defer conn.Close()Putting everything together
Now both client and server compile this same contract (.proto file), and they generate native code from it. That code handles all the serialization, deserialization, function calls, and network calls.
So when we write:
user := svc.GetUser(&GetUserRequest{LastName: "Sarwar"})It uses the contract to:
Serialize the request into binary
Send it over HTTP/2
Deserialize the response into a native
Userstruct (which was auto-generated)
Let’s look at all these step-by-step —
The stub knows that the method
/user.UserService/GetUseris registered with it.It internally makes a call like
err := c.cc.Invoke(ctx, "/user.UserService/GetUser", in, out, opts...)And then, gRPC converts it into a fully qualified method name like -
/<package>.<service>/<method> -> /user.UserService/GetUserSending over HTTP/2 —
https://api.example.com:50051/user.UserService/GetUser
We don't see all these steps done by stub; all those are abstracted away.
We don’t see JSON. We don’t write endpoints. We just call a function, exactly like we imagined in our naive design earlier.
Under the hood
I found this diagram, which makes the whole flow from client to server (or vice-versa) quite clear.
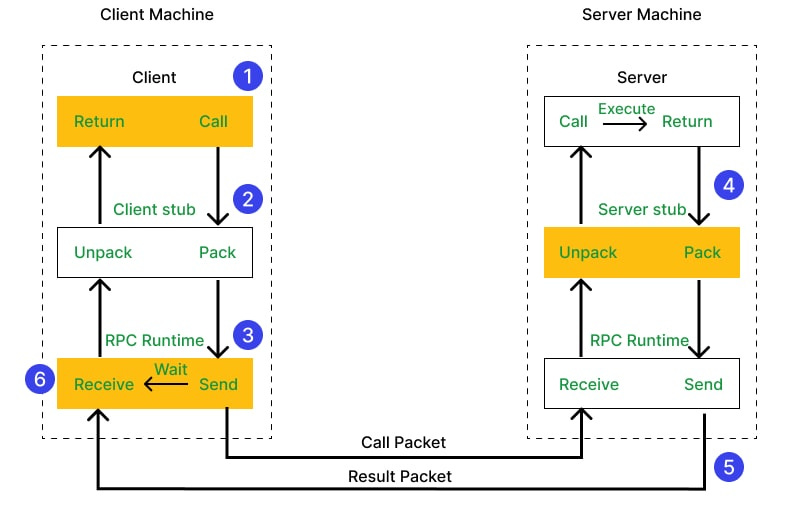
{kind=link}
Retries, Timeouts, Errors
Timeouts
gRPC solves this with context propagation, like in Go — context.WithTimeout or context.WithDeadline
Behind the scenes, this context does two things:
It propagates the timeout to the server via gRPC metadata.
If a timeout happens, both the client and server cancel the operation, freeing up resources
Retries
In REST, we create retry logics with exponential backoffs, according to the status code and timeouts.
Here in gRPC, it’s baked into the protocol itself.
We can configure retries, with each method in a config file, according to the error codes that RPC sends back —
name:
- service: my.UserService
method: GetUser
retryPolicy:
maxAttempts: 4
initialBackoff: 0.1s
maxBackoff: 1s
backoffMultiplier: 2.0
retryableStatusCodes:
- UNAVAILABLEIf the server is temporarily down (
UNAVAILABLE), the client will retry.Retries are exponential backoff-based
Error Model
Every error is a structured object with:
A code (like
UNAVAILABLE,INTERNAL,DEADLINE_EXCEEDED)A message
Optional metadata (headers, trailers)
It’s more detailed than traditional REST, which offers just the status code and JSON with the error message.
There are other things that gRPC provides, authentication, middleware, load balancing, and other things, which are quite useful when running RPC on prod.
Streaming in RPC
In RPC, we can communicate in both directions, like a WebSocket in HTTP/1. But it’s much easier and more efficient.
There are multiple RPC types. Let’s look at them and how they enable streaming.
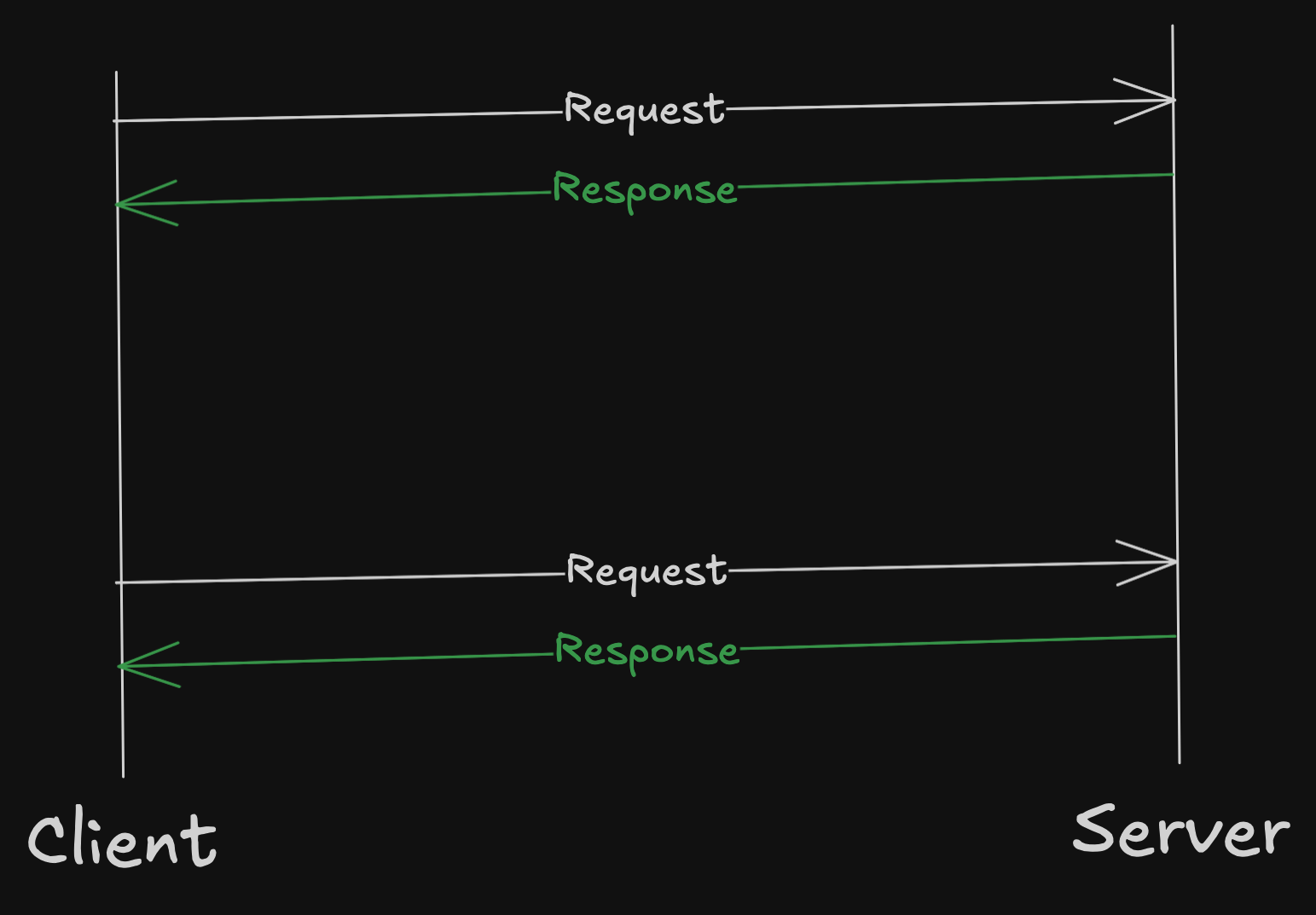
Unary (Classic Request-Response)
This is the traditional REST kind of request-response format.
rpc GetUser(GetUserRequest) returns (User);The client sends a single GetUserRequest.
The server responds with a single User
Server Streaming RPC
The client sends 1 request, but the server keeps sending back a stream of responses.
rpc GetAllUsers(FilterRequest) returns (stream User);Client says: “Give me all users whose last name is ‘Sarwar’.”
The server replies with a stream of User messages.
Example Use Case
Log tailing (new logs are streamed continuously)
Live search results (all the new users created with the last name as “Sarwar”)
Fetching large datasets in chunks (a huge 120 GB file, which can’t be sent in a single response, so it’s chunked into 12 GB files each, being sent continuously)

Client Streaming RPC
Just like we saw in server streaming, but this time the client sends multiple continuous requests, and the server responds with a single response.
rpc UploadLogs(stream LogEntry) returns (UploadSummary);Example use case
Let’s say we are sending a huge data (like logs, metrics, events), but we can’t send it all at once, so we break down the data into chunks and keep sending the chunks continuously.
This is useful when we don’t want to hold all the data in memory and want to push entries one by one.

Bi-directional Streaming RPC
It’s like a WebSocket, but with protobufs, making it faster than traditional websockets (as it’s encoded/decoded in binary).
rpc Chat(stream ChatMessage) returns (stream ChatMessage);Example use case
Real-time chat
Multiplayer game state
Live collaborative editing

gRPC treats streaming as native. The client/server just calls .Send() and .Recv() in loops. Everything else, the encoding, buffering, and flow control, is handled by the gRPC runtime over HTTP/2.
This makes it ideal for low-latency, high-throughput, or live applications.
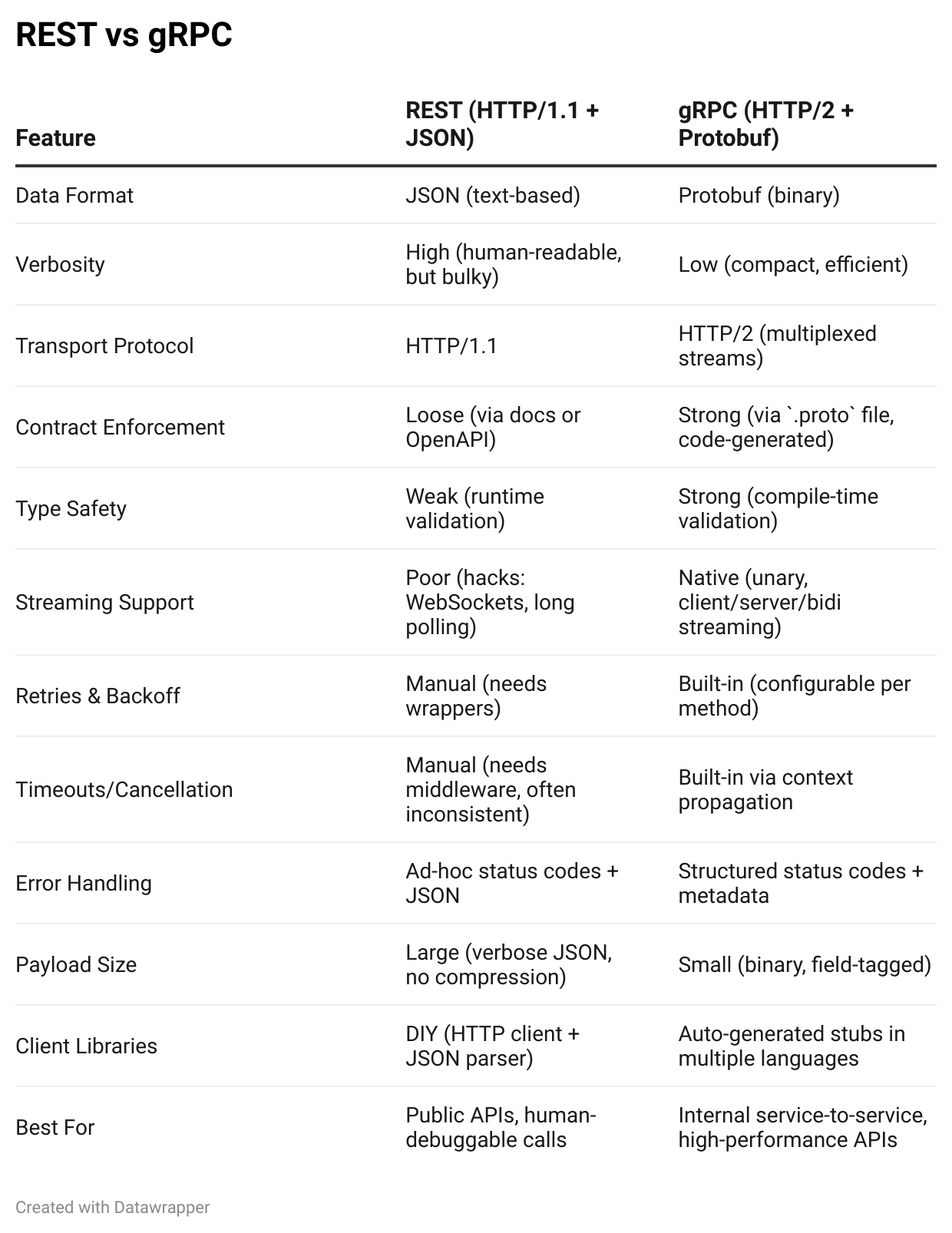
Difference in the payload of REST and gRPC
Let’s assume we want “Get all the users with id = 42”.
We will look at the payloads for both REST vs gRPC to understand the difference.
REST (JSON over HTTP/1.1)
POST /getUser HTTP/1.1
Host: api.example.com
Content-Type: application/json
{
"id": 42
}Text-based (verbose)
Human-readable, but inefficient for machines
The server parses the endpoint (
/user) and the body (JSON)Payload: ~30–40 bytes even for this tiny request
Needs runtime parsing of strings, types, and structure
gRPC (Protobuf over HTTP/2)
:method: POST
:scheme: https
:path: /user.UserService/GetUser
content-type: application/grpc
grpc-timeout: 1000m
(binary protobuf payload)
08 2ANote that the above is a simplified view of the payload; the original payload might be more complex and not this readable.
Binary format:
08 2Ais Protobuf forid = 42Content-Type is
application/grpc(not JSON)Function is mapped from the path:
/user.UserService/GetUserClient and server already agree on input/output types
Much smaller payload size (often 10x smaller than JSON)
No runtime parsing; fields are decoded directly into memory
Comparing REST vs gRPC
When to use REST
Building public APIs meant for third parties
Human readability matters (debugging via Postman/curl, easy JSON logs)
Want broad language support without forcing tooling (clients in Python, PHP, etc.)
OK with a stateless, request-response model (no streaming)
When to use gRPC
Building internal service-to-service communication (microservices, infra systems)
Need high performance — smaller payloads, faster parsing, lower latency
Want strong contracts — schema-enforced APIs, auto-generated clients
Need streaming
Want built-in support for retries, deadlines, and structured errors
We haven’t touched about multiplexed streams here. To know more, I have covered it in a previous post that can be considered as a prerequisite to this one.
Wrapping Up
At the end of the day, gRPC isn’t magic, like anything; if we get deeper, the magic goes away.
It’s just a system that takes a very basic need, “call a function on another machine”, and builds the shortest, cleanest possible path to make that feel local.
It does what REST never really tried to do: give us strong contracts, type safety, efficient communication, and streaming, all out of the box.
And yeah, this post wasn’t about memorizing API calls or Protobuf syntax. It was about understanding how we got here. What problems are we solving? What happens when we remove the illusion and actually trace the deeper questions underneath?
This post wasn’t about building our own gRPC. It was about understanding that great systems aren’t magic, they’re answers to well-asked questions.
That’s all for this week, see you next week with something more interesting.
Stay tuned.