

Why grep is Fast: NFA, DFA, and Regex Simplified
My most technical post, ever!

If you’ve ever touched Linux, chances are you’ve come across the grep command. If not, don’t worry — you're about to take a deep dive into one of the most powerful and surprisingly fast search tools in your terminal.
grep [options] "pattern" file/folder(s)Introduction to grep
grep, is a blazingly fast search for searching any pattern in a file, folder, or an entire directory.
The thing that makes grep unique is how fast it processes the query, because let’s be honest, searching a pattern in a huge file, folder is no joke.
grep searches for lines in a file that match a pattern. The pattern can be a simple string or a full regular expression.
You know me, if I have introduced grep I would surely get deep into how it works.
How grep works?
Step 1: Reading the file line by line
grep works line by line, checking if a pattern matches in each line.
char line[1024];
while (fgets(line, sizeof(line), f)) {
// process each line searching for the pattern
}Why? fgets() reads one line from the file at a time. This is memory-efficient and allows grep to process huge files without loading the whole thing into memory.
Step 2: Check if Pattern Matches (Literal Search)
If the pattern is not a regex, grep uses a substring search
if (strstr(line, pattern)) {
printf("%s", line);
}Why strstr?
It returns a pointer to the first occurrence of
patterninline, or NULL if not found.This is a basic substring search, used when regex is not needed (
grep -For basicgrepon fixed strings).
Step 3: Use Regex When Needed (Regex Engine)
This is the real reason for this blog: tighten your seatbelts, because things are about to get interesting.
If a regex is provided (grep -E), grep must:
Parse the regex
Compile it into a Finite Automaton (NFA/DFA)
Run the automaton on each line
Why automata?
Regex matching is equivalent to recognising a regular language, and finite automata are used to recognise regular languages efficiently.
Not being from a computer science branch, I had absolutely no idea what the above meant, so as always, I went deeper. Let’s go there.
Regex Match
You must be wondering about the LeetCode question — Regular Expression Matching.
Well, yeah, kinda. We are going to do the same problem but quite differently. The way it’s done in production, not just for the sake of the interview.
Let’s look at this regex pattern - ab*c
What kind of strings will this match?
ac
abc
abbc
abbbc
And what kind of strings will this not match?
a
acx
acb
To match if a pattern follows this regex, we create an NFA.
NFA (Nondeterministic Finite Automaton)
It can be considered a machine where the states change dynamically on certain inputs.
At each step, the NFA “forks” into multiple possible futures (states) and keeps track of all of them. It’s like a mini parallel universe engine.
No recursion, no lookahead, no backtracking in this version, it's just state transitions and ε-moves. So elegant and predictable.
εmeans epsilon (i.e., move without consuming a character)For the below state diagram, s5 is the accepted final state that a string needs to reach to get matched with the given regex
The NFA state diagram for regex - “ab*c” is below.

I know this diagram feels alien right now (I felt the same initially), but trust me, it will make sense in a while.
To understand this, assume all the paths from s0 → s5 correspond to some string that matches the regex pattern.
Let’s list down —
aεc→ means we match‘a’, skips the rest, and then matches with‘c’, like — acaεbεc→ means we match‘a’, then match exactly 1‘b’, then‘c’,like — abca
εbεbε…bc→ means we match‘a’, then match > 1‘b’,then‘c’, like — abbbc
You can see that moving from s2 → s3 → s2 is a loop, meaning we can club multiple b’s together as in the case of regex (b*).
State Transition Table
It’s easier to tabulate the transition from different states, it will be really helpful for matching a string against a given regex in the future.

Simulating the NFA on input “abbc”
Step 0: Initial States
Start at
s0No ε-moves from
s0Active state set:
{s0}
Step 1: Read 'a'
From
s0,'a'leads tos1From
s1, follow ε-transitions:s1 --ε--> s2s1 --ε--> s4
So:
After
'a', states ={s2, s4}
Step 2: Read 'b'
We now process each state:
s2hasbtransition →s3From
s3, ε-transitions:s3 --ε--> s2s3 --ε--> s4
So after 'b', from s2 → s3 → ε → s2, s4
s4has nobtransition → ignored
After 'b', states = {s2, s4} again (looped via b*)
Step 3: Read 'b' again
s2→b→s3→ ε →s2,s4s4ignored
After 'b', states = {s2, s4} again
Step 4: Read 'c'
Now we process 'c':
s2noctransition → ignoreds4hasc→s5(accepting state)
So:
Final state:
{s5}
We reached the accepting state after consuming all input.
I tried creating this state animation, I hope this makes it clearer (even slightly is okay).
Why is s2 looping?
Because of the b*, it allows:
zero
bs (go froms1→s4directly)one or more
bs (loop betweens2ands3)
Each b keeps us in {s2, s4}, so we are always one step away from the c.
That might have felt overwhelming, but we’ve just manually simulated an NFA.
NFA vs DFA
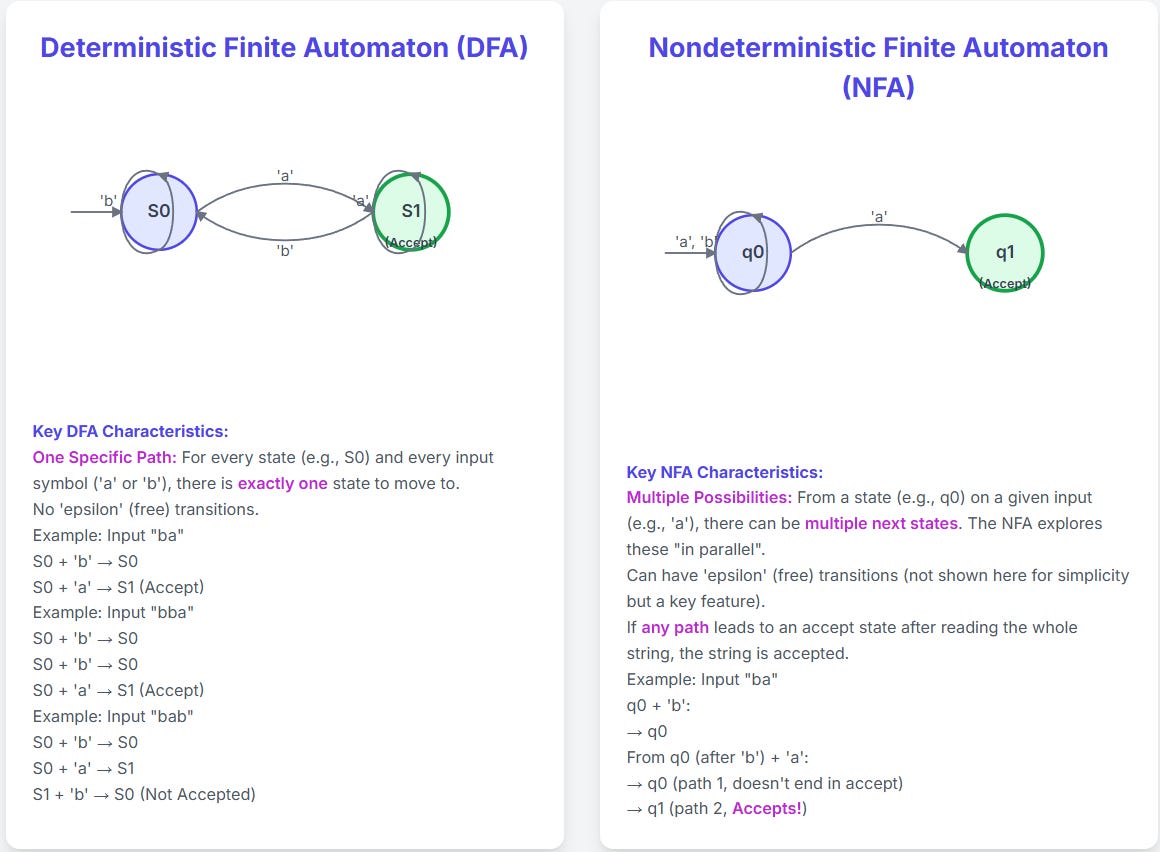
Non-Deterministic Finite Automata vs Deterministic Finite Automata — these are some heavy words, let’s understand WHY we need to understand them together.
Let’s understand them with an example of a maze —
DFA (Deterministic Finite Automaton)
At every junction (state), for any signal (input like ‘a' or 'b'), there's only one clear path forward. No choices, no confusion.
Example: Recognising exactly "cat". Each letter leads to one specific next step.
NFA (Nondeterministic Finite Automaton)
At a junction, for a signal, you might have multiple paths, no path, or even "free teleports" (epsilon transitions) to another state without needing a signal.
An NFA "guesses" and explores all options at once. If any path works, it's a match!
Example: Recognising strings ending in "at". An 'a' could be the 'a' before 't', or just some random 'a'. The NFA explores both ideas.
Why Two Types?
NFAs are often easier to design initially (YES, what we did earlier was the easier one!).
DFAs are what often get implemented because they're faster and more straightforward in execution.
Any NFA can be converted into an equivalent DFA, though the DFA might be bigger.
Now that we understand (or maybe don’t understand) about NFA/DFA, let’s see the time complexity of this and how this is better than normal backtracking.
Time & Space Analysis
Space Complexity
The amount of memory needed depends mostly on the size of the NFA itself (how many states and transitions it has), not on how long the input string is. It's like needing a map of a city – the map size doesn't change based on how long the trip is.
Time Complexity
For each character we read in the input string, the NFA simulation does a certain amount of work. This work involves figuring out all the states the NFA could possibly be in after reading that character, including following any "epsilon" (free) moves. The amount of work per character is limited by the size of the NFA.
Since the work per character is roughly constant (determined by the NFA's size), the total time taken is directly proportional to the number of characters in the input string.
That's why it's called linear time complexity to the input string length – if we double the string length, the simulation takes roughly twice as long.
The NFA's size affects how much work is done per character, but the relationship between string length and total time is linear.
Endnotes
The other day, I was discussing this algorithm with one of my friends, and he told me this algorithm is something we are taught in our computer science course, but we don’t appreciate it enough. If we knew where these are used (in grep!), then we might have paid more attention to it.
To be completely fair, this isn’t understood by many; it doesn’t have to be understood by many. All I want is for you to appreciate how amazing this algorithm is and how big of an impact it has.
Let me know if you want a small implementation of this algorithm (I have already implemented it while trying to understand).
I think this might be my most difficult blog to create, ever. Because the sheer effort it took to understand and then visualise this was too much. But yeah, that’s why I enjoyed it.
That’s all for this week, we will meet again next week, hopefully with something lighter!
Stay tuned.
Bonus
Since you read till here, you can find the source code where the GNU regex library uses DFA (potentially).

great efforts man, nicely written