

The Magic Behind One-Click Checkout: Understanding Idempotency
Exploring how idempotency keys keep your orders correct, even when networks fail

While making a payment, if we end up submitting it twice, we don’t get charged twice.
While ordering something on e-commerce website, if we click on “buy” multiple times, we don’t get multiple orders.
While pressing the elevator call button multiple times, it doesn’t come fast or change the request.
All the above examples are for systems that are “idempotent”.
Idempotent operations are operations that produce the same result regardless of how many times they are executed.
It looks simple on the surface, “just check if we already succeeded”, but the deeper we go, more problems, and brilliant solutions we will find to attain idempotent operations.
I believe building idempotency in any backend architecture is complex but quite rewarding. Designing it is complex, but it makes our lives easier.
Why idempotency keys?
Imagine this scenario.
You are shopping on Amazon, and you have a few items in the cart. You want to checkout and make payment. You clicked on “Checkout”, made your payment but for some reason the screen kept loading.
You reloaded the page, and went back to your cart. You still see your items there, that means the “Checkout” was not successful. So you clicked on “Checkout” again, and this time, the payment got succeeded, and your orders are placed.
Now, what happened to the first time you made payment? Will you get doubly charged? But that doesn’t seem to be so, you don’t see multiple transactions in your card.
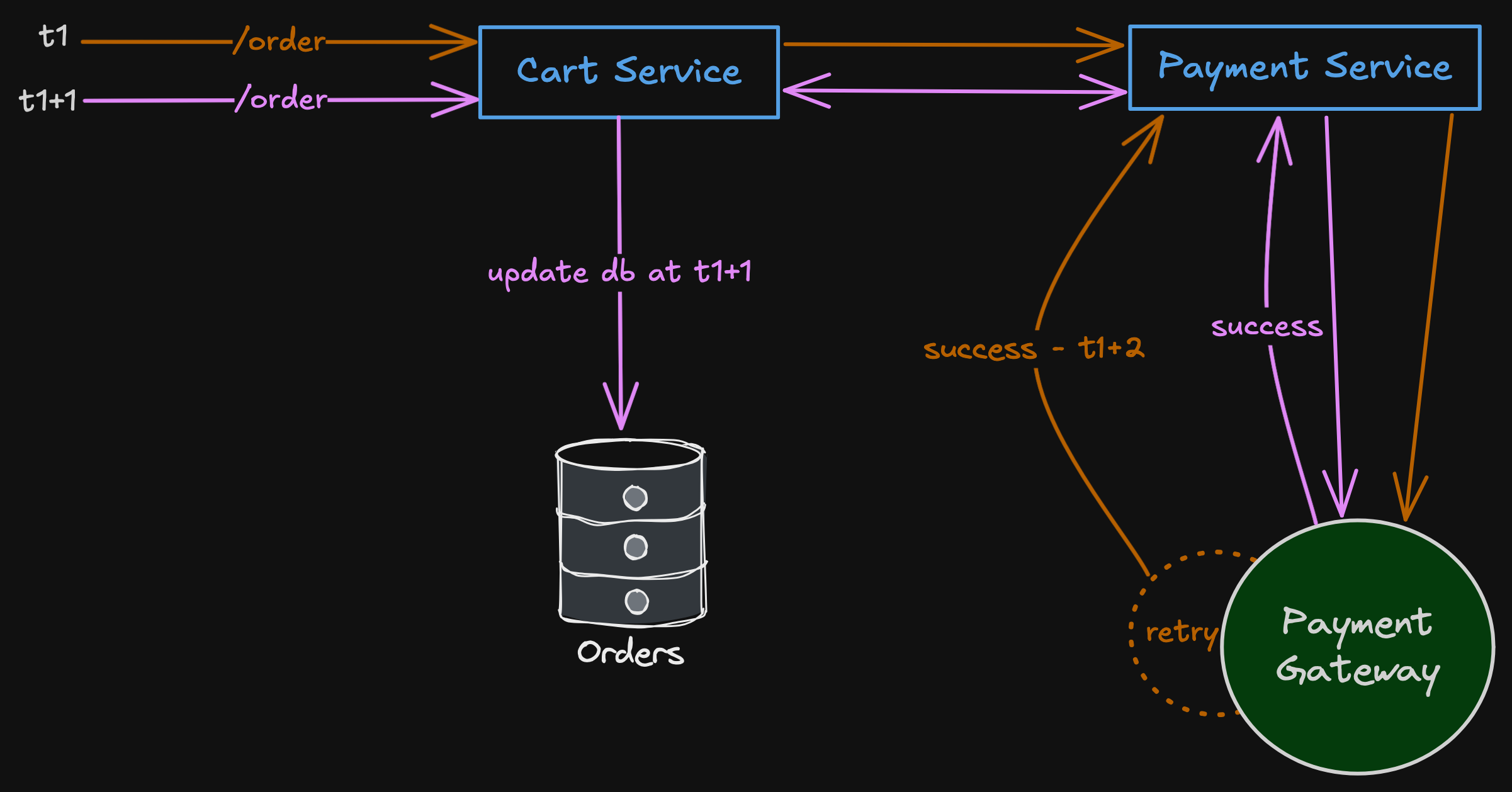
Let’s brainstorm few ways in which we can design something like this.
The Core Idea — Idempotency Key
We need some kind of “key”, which will always be unique for a particular order, or cart. So that, no matter how many times we send that key, that particular order can always be uniquely identified based on that “idempotency key”.
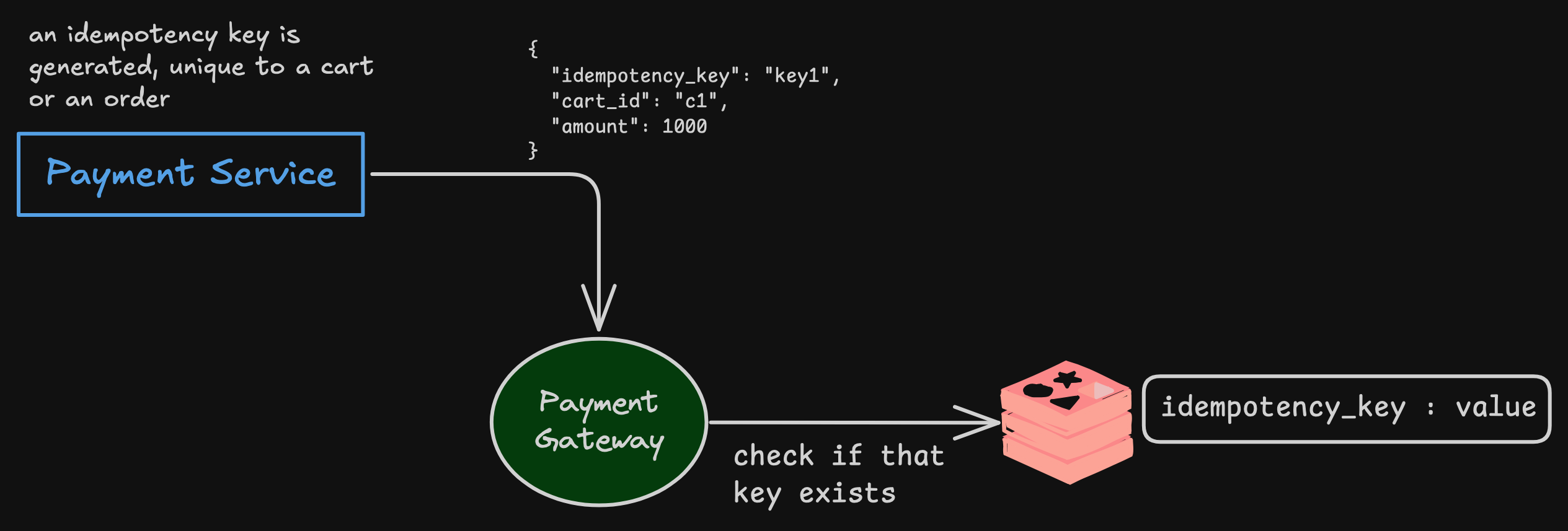
The Payment Service can generate that key, and attach it to the request sent to the Payment Gateway. It can be something like this —
{
“idempotency_key”: “key1”,
“cart_id”: “c1”,
“amount”: 1000
}Storage Gateway
Most gateways implement this as:
Maintain a persistent store (usually Redis/DB) keyed by
idempotency_key.Value =
{request payload hash, result status}.On new request:
If key doesn’t exist → process & store.
If key exists:
If payload differs (same key but
amount=2000instead of 1000) → error (Idempotency key reuse with mismatch).If payload matches → return stored result.
This prevents both accidental duplicates and malicious replay attacks.
Choice of Database
Redis: It’s fast, great for low-latency checks. But what if the Redis cluster fails? What if a node goes down right after a payment request is initiated but before the result is stored? This can lead to a “lost” state, where a user sees the payment succeed but a service sees no record of it, potentially triggering a re-payment attempt on the user’s end.
Database: A relational database offers strong ACID guarantees. A
SELECT ... FOR UPDATEor a unique constraint on theidempotency_keycan provide the atomicity needed to prevent the race condition. The trade-off is higher latency compared to Redis. The most robust systems often use a hybrid approach: Redis for a fast initial check, with a fallback to a durable, transactional database for a true record.
Generating Idempotency Keys
We saw that we need some kind of idempotency keys generated that can identify a piece of object uniquely. So normally, the problem becomes, “how to generate such keys, and what should such key consist of?”
Let’s look at what we need for our idempotency keys —
An order should be uniquely identified from it
Let’s say, if there is a change in some items of that cart (e.g., the quantity is changed), then it should be a new key
The keys should be generated fast, because there are a lot of orders happening at the same time
First, let’s look at where should this idempotency key can be generated?
Generating keys at Payment Service
Let’s look at some pros and cons for generating keys at the Payment Service.
Pros:
Centralized at payment layer.
Can reuse across retries since Payment Service is the one communicating to the gateway.
Cons:
Payment Service doesn’t really know business logic (cart vs order changes).
If it generates just a random UUID, we will lose the “order uniqueness.”
Generating keys at Order Service
Let’s look at some pros and cons for generating keys at the Order Service.
Pros:
Order Service knows the business logic: when a cart changes into a “new order state,” it should force a new key.
It can tie directly to
order_idor even a hash ofcart_id + items + quantities + total_amount(something like that)Order Service is also the naturally responsible for “what is being purchased.”
Cons:
It’s more complex (need a deterministic way to decide key boundaries).
What should the key contain?
As discussed earlier, it should be —
Unique per order version (so retries map to same order)
Sensitive to cart changes (so updated cart → new key)
Fast to generate
What if we use something like the following —
idempotency_key = hash(cart_id + cart_state + amount)Where:
cart_id= unique cart identifier.cart_state= serialized, sorted list of items + their quantities.amount= total charge (some kind of checksum to avoid mismatched retries with different amount).
{
“idempotency_key”: “sha256(c1:[item1x2,item5x1]:1000)”
}We can store the idempotency keys along with the order_id in our DB.
Deterministic vs Random Keys
In the section above, we tried to make our keys “deterministic”, meaning we can probably recreate the cart state just by looking at the keys.
But why do we need the keys to be deterministic? We can make them random UUIDs as well. Let’s look at some pros and cons of using deterministic keys vs random keys.
Random key (UUID per checkout attempt)
Random keys require a stateful “key generator” component that must durably store the UUID before the payment call. This introduces a tight coupling to the database or an external store and a single point of failure (or at least, it’s in the critical path).
Flow: when user checks out → generate UUID → store it with
order_id.Pros:
Clean separation of concerns (the key is just a token, not derived from business logic).
We can add/change fields later without changing key generation logic.
Cons:
Requires durable storage at the moment of checkout. If generation/storage fails, we can’t retry deterministically, we will lose the linkage, and that would block ordering
So with random keys, our reliability depends on guaranteeing durable persistence before payment call. That means the Order Service must atomically:
Create order record,
Generate/store idempotency key,
Then call Payment Service.
If step 2 fails, the whole order attempt fails.
Deterministic key (derived from cart snapshot)
Deterministic keys align with a more stateless approach. The key itself is the state, derived from the request. Services can be horizontally scaled and don’t need a shared, durable key store at the moment of request initiation. If a service instance crashes, a new one can re-compute the key and continue.
Flow: hash(cart_id + cart_state + amount).
Pros:
Can be recomputed anytime from source of truth.
No need for strong storage guarantees at checkout moment, retries are always reproducible.
Cons:
Coupling: the key encodes business logic. If our cart model changes, our key generation logic must evolve carefully.
It comes down to what we will value more from our system —
If simplicity of retries is critical, and if we want it to be stateless → deterministic. We never have to worry about key loss.
If abstraction and flexibility is critical → random wins, but we need absolutely consistent DB transactions to never lose the key.
Wrapping Up
Idempotency in e-commerce may feel straightforward, clicking “checkout” twice shouldn’t double the order. Yet, as we’ve seen, there are subtle design choices to make, from who generates the key to what it contains and how we store it. These choices ensure reliability and a smooth user experience.
But this is just the beginning.
The real challenge emerges when a single action sets off a chain reaction across multiple microservices, queues, and distributed payment flows.
In Part 2, we’ll dive deeper into how distributed systems handle retries, conflicts, and the crucial role of message queues in achieving true end-to-end idempotency at scale.
We’ll explore the difference between at-least-once and exactly-once delivery, tackle the problem of race conditions with atomic operations, and discuss how to design for resilience in the face of service failures.
That’s all for this one.
Great article, indeed! Normally I use the order_id, or the ID related to the subject we’re discussing, as the idempotency key, which works wonderfully in the SQL world. However, whenever I have a key-value store or a NoSQL DB like Cassandra, I prefer hashing the content to create an idempotency key, since it adapts better to that model.
I’m just wondering about this part from your article:
total charge (some kind of checksum to avoid mismatched retries with different amount).
Is this checksum applied so that we can identify changes in each product’s price, and not rely solely on the total amount? The total could theoretically be the same even if individual product prices have changed.