

How Facebook built Cassandra
What happens when availability and throughput becomes the system's top priorities?


When choosing between LSM vs B+ trees, we have to consider the type of workload (write vs read) and choose accordingly.
Systems optimized for reads — like traditional RDBMS with B+ trees — struggle under heavy write pressure. And vice versa, write-optimized engines like LSMs trade off read latency (with eventual consistency).
But it’s not always that simple. Sometimes, we need something in the middle — a database capable of handling millions of writes per second, while being able to be highly available, horizontally scalable, and which can also provide fast reads.
Well, yeah, this is the combination we are talking about —
Write heavy
Fast queries
Horizontally Scalable
Distributed, highly available
Writing all these down feels like a contradiction in itself. Most databases force a compromise somewhere.
But what if we couldn’t afford to compromise? That’s what led to building something like Cassandra.
Beginning of Cassandra
Cassandra was built when Facebook was implementing its messaging feature (back in 2007) — fast search across billions of messages per user, replicated globally, available 24/7.
They needed:
Writes from all over the world (new messages, user actions)
Data to be available even if a region or data centre goes down
Fast lookup by key (user ID, message ID, etc.)
They looked at:
RDBMS: Great at joins and consistency, but not built for high write volumes or multi-region distributed systems.
Document-based database: Document store, flexible schema, easier scaling — but at that time, MongoDB had weak consistency models and limited support for sharding and replication.
So they couldn’t use the traditional databases at the time; they needed something for their specific use case.
Let’s put ourselves in the shoes of a Facebook engineer working on designing such a system.
How do we design a database with such constraints?
Let’s recap what our requirements are —
Write-heavy workloads (millions of messages/sec)
Global replication (data centres in multiple locations)
High availability (no single point of failure)
Fast key-based search (messages per user, chats, etc.)
1. Write-heavy
If we are designing for a heavy-write system, the LSM tree provides a great option.
Writes are appended to a memtable and later flushed to disk as sorted SSTables.
Background compaction takes care of merging all the SSTables
This means writes are fast, like really fast.
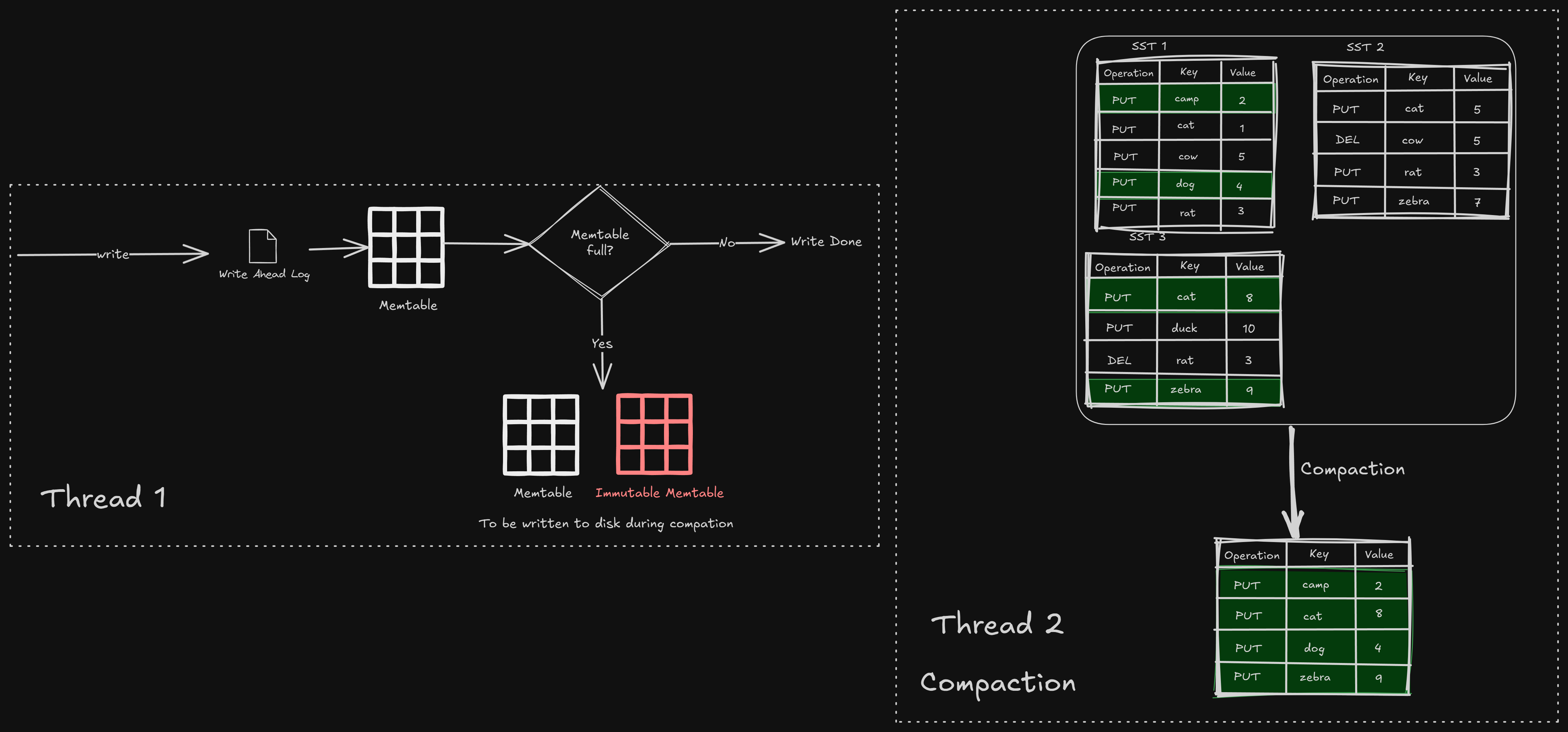
The only downside is that reads would be slower, since reads require us to scan multiple SSTables.
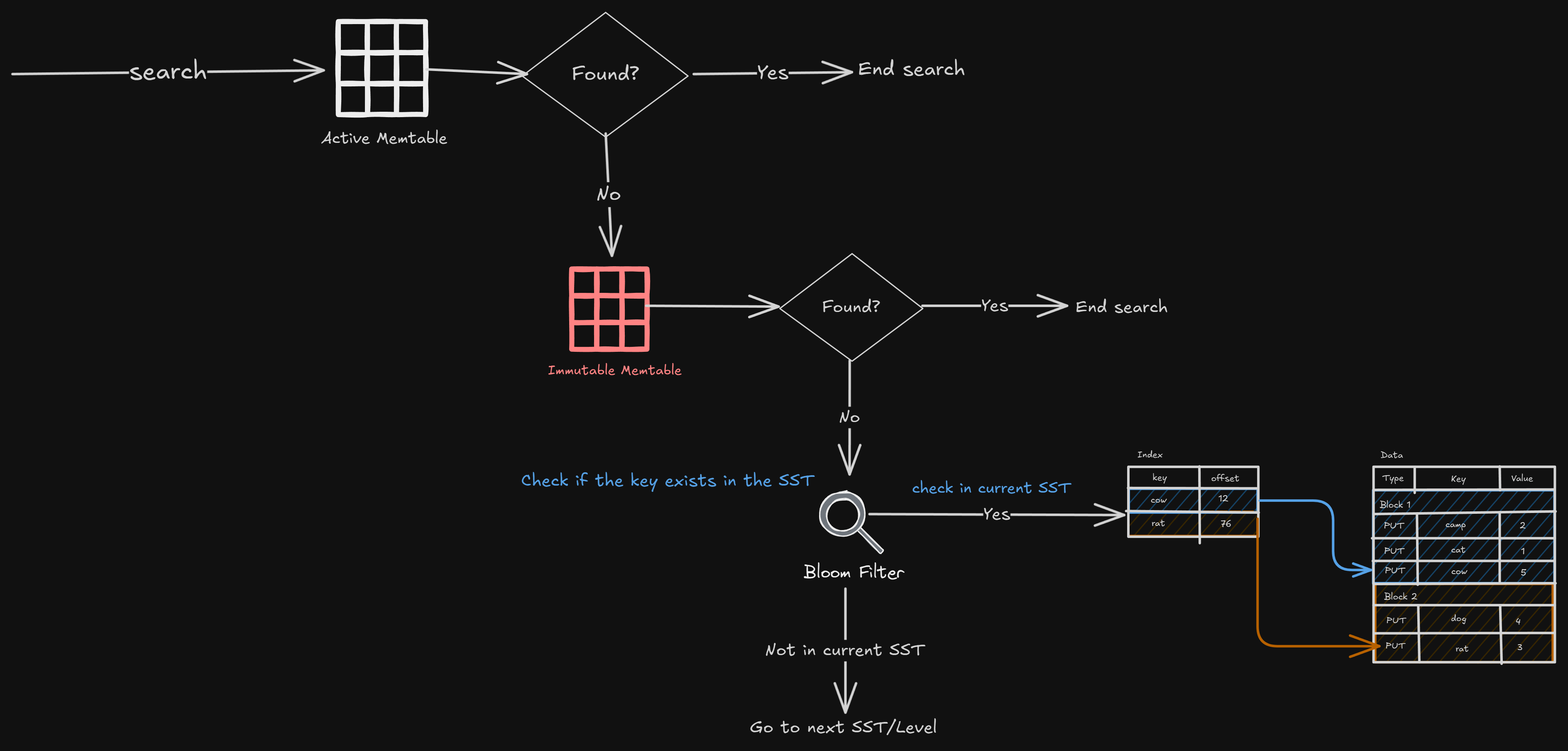
So we optimize for write throughput.
Decision: Use LSM-based storage for write-optimized behavior.
2. Global Distribution
If a user sent a message from India, that data should be sent to a local server (in Asia).
Then, the message should be replicated to other servers (e.g., US, Europe).
Also, the message should be searchable from anywhere.
How to do it? Let’s look at each of these requirements and the techniques we can use.
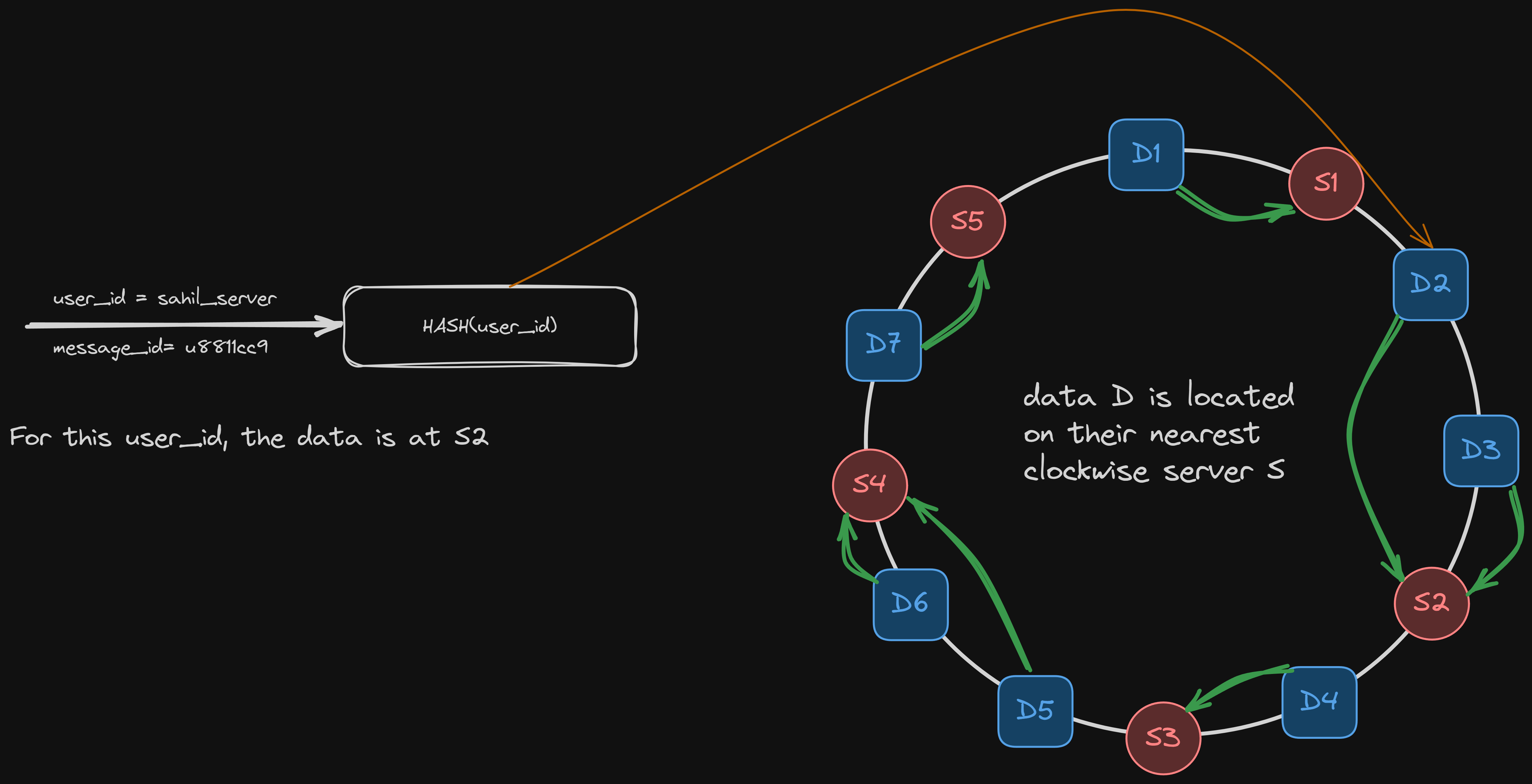
Consistent Hashing
We partition the data across nodes based on a hash of the primary key, maybe (user_id). This ensures even load distribution and also gives us minimal data movement when adding or removing a node.
You can read more about consistent hashing here.
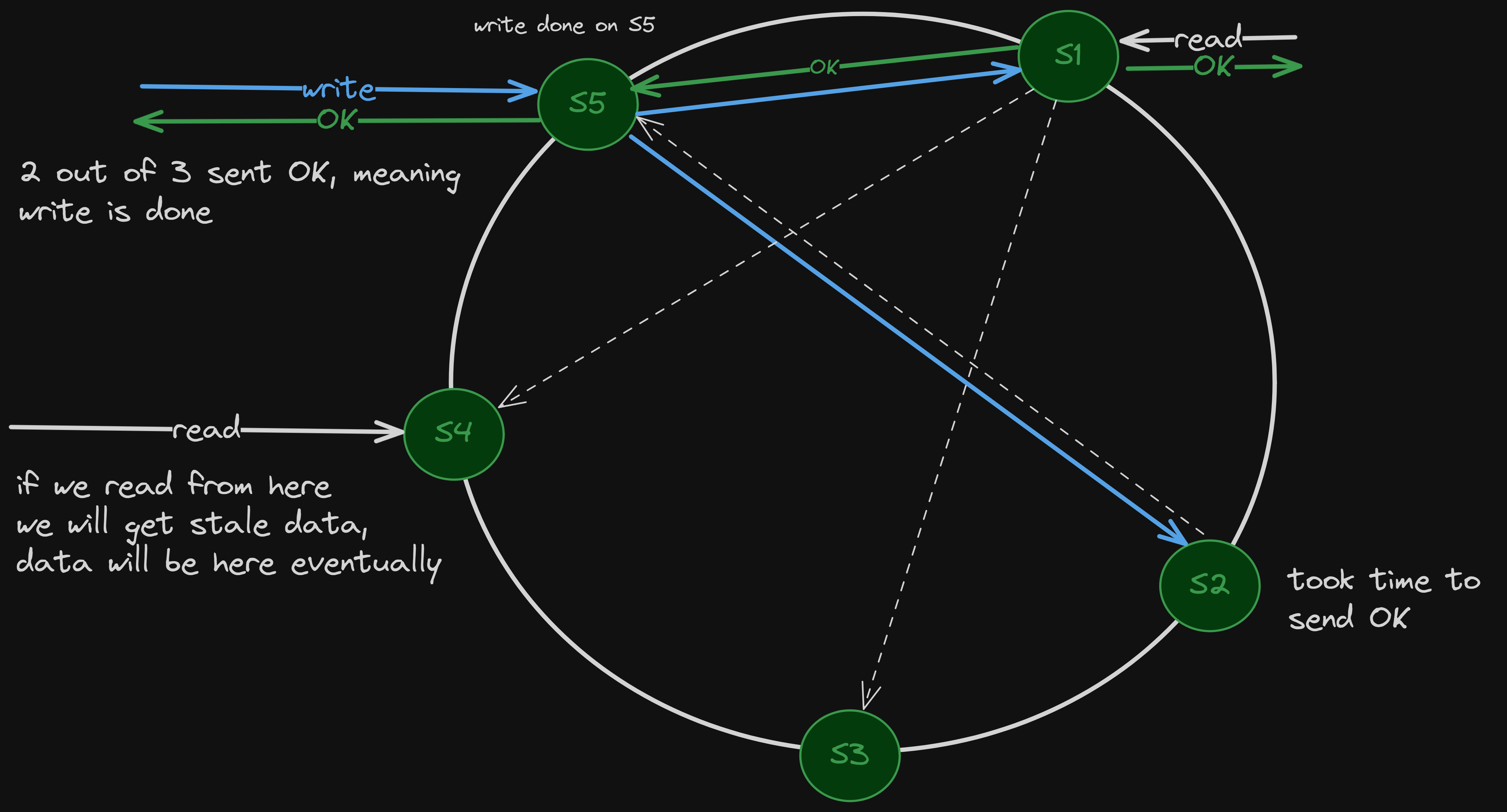
Replication
Instead of a leader-follower model, we do the following —
Data is written to N nodes (say, 3),
We can configure the consistency level per request (e.g., read from 1, write to 2 out of 3), so we can tune accordingly (CAP theorem)
Gossip Protocol
Each node regularly shares state with a few other random nodes. This means:
All nodes learn about each other.
Node state (up/down, data) is shared.
No central metadata store, the system is truly peer-to-peer.
This distributed, peer-to-peer exchange ensures all nodes eventually converge on the same data of the clusters in the network without a single point of failure.
I have covered gossip protocol in the past, read it here.

Decision: We use consistent hashing for partitioning, gossip for coordination, and a replication model which can be tuned.
3. High Availability
We are designing for availability, that’s our top priority; we have to assume “if something can go wrong, it will go wrong”.
The system must:
Detect failures quickly,
Route traffic to healthy nodes.
Make sure that no write is lost even during network partitions.
Cassandra achieves this through some amazing design and algorithms. Let’s look at them in more detail.
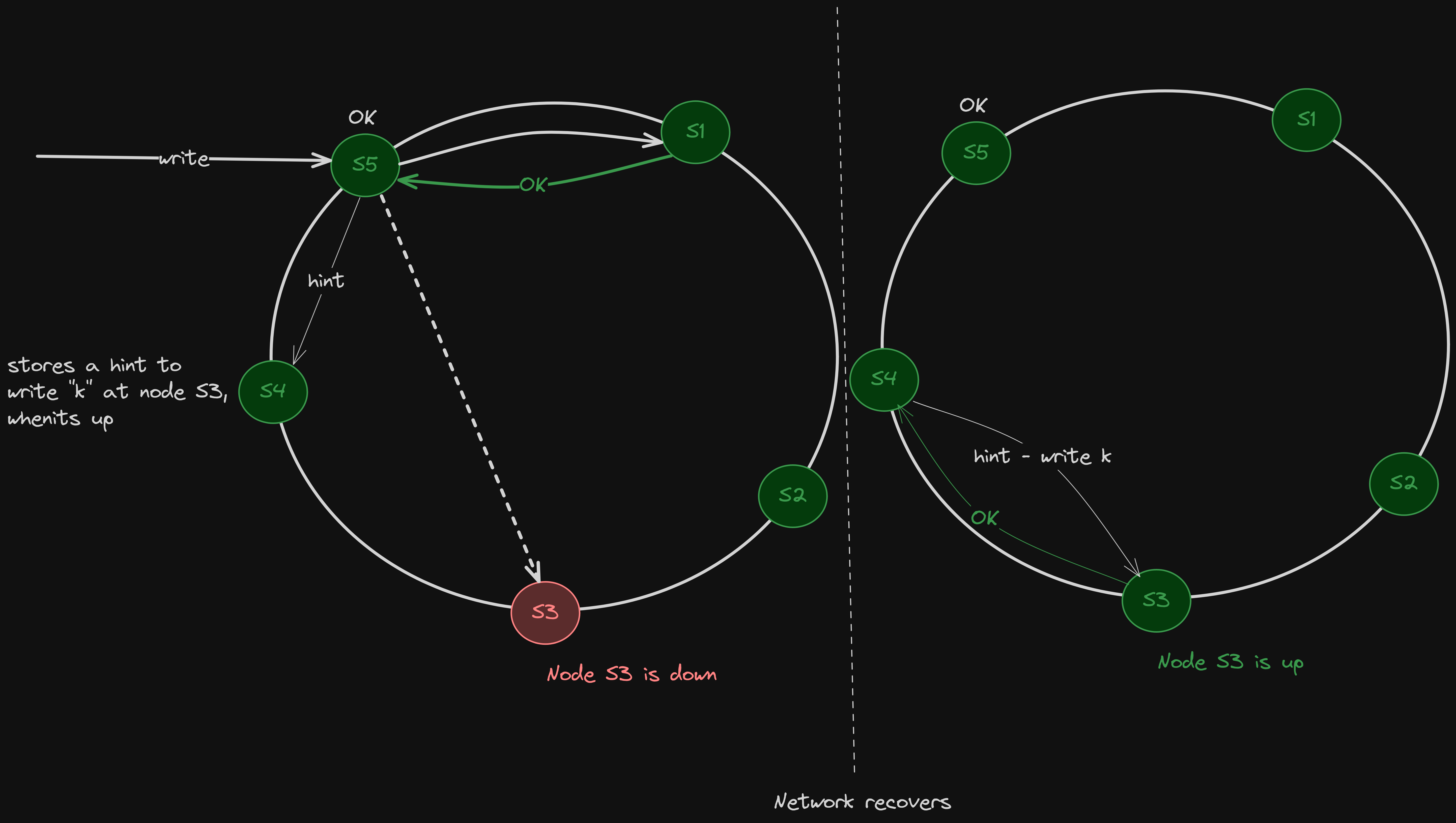
Hinted Handoff
If we have a replication factor of 3, and we are writing a key. If one of the replicas is down, either we will lose availability, or the write will fail.
Instead of failing to write, Cassandra does something clever:
Node A is down. We can store a hint, like , a note that says ‘this write needs to go to Node A when it comes back’.
That hint is stored on one of the live nodes (called the coordinator) and replayed later once Node A recovers.
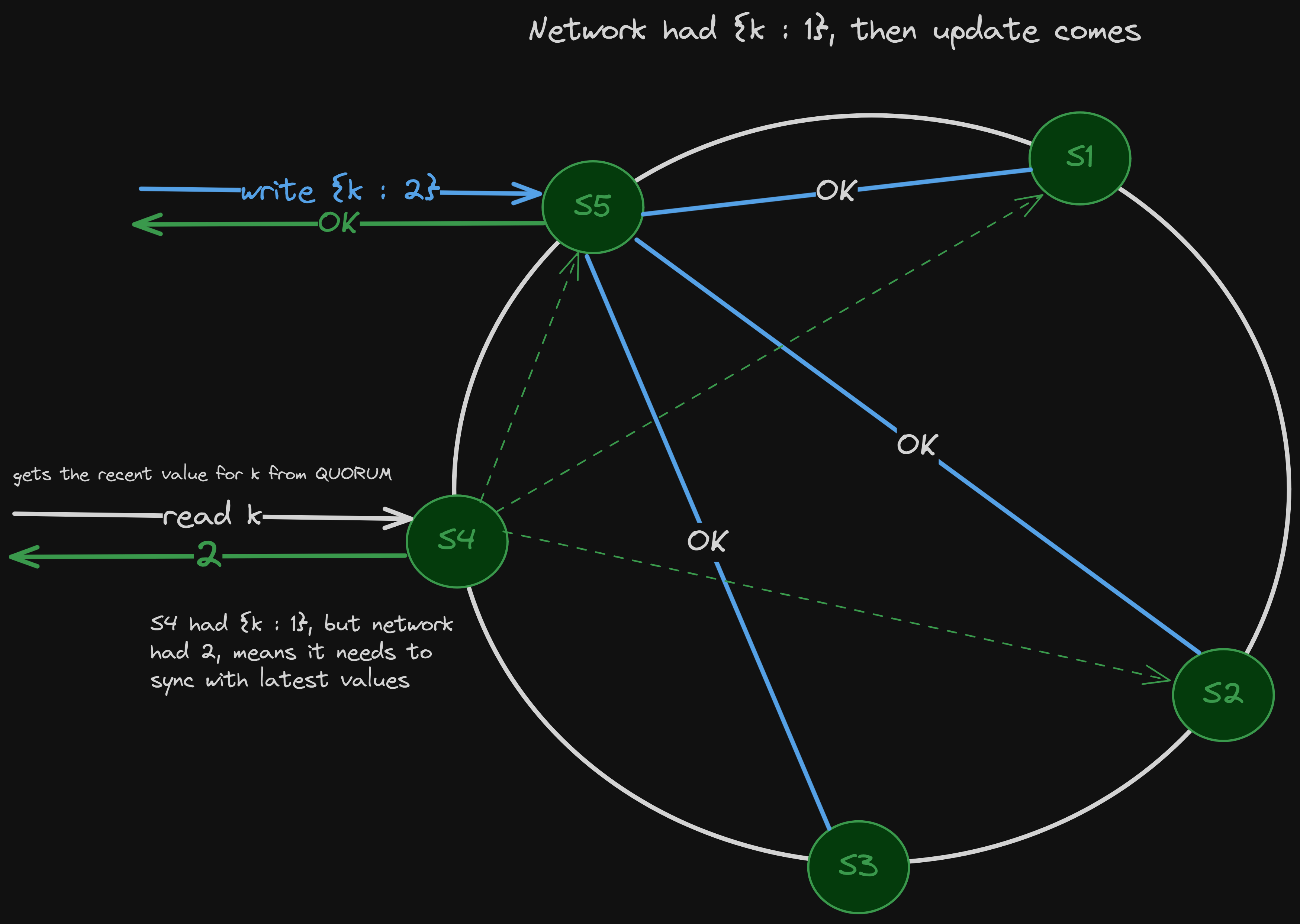
Read Repairs
In a distributed system, some replicas may have stale or missing data.
Since reads are from multiple replicas, they don’t all agree.
When we perform a read, Cassandra queries multiple replicas and compares the results across them. QUORUM (a sufficient number of people or nodes are participating in a decision-making process), to make sure multiple replicas agree on the data before sending it to the client.
If we detect stale data, we return the most recent value to the client.
And in the background, we push the correct value to the stale replicas.
So Cassandra uses reads as an opportunity to heal the system.
Merkle Trees
How do we know if two replicas have inconsistent data, over multiple servers, across millions of partitions and keys? We can’t compare each row; it would be too costly.
Merkle Trees are hash trees; each node stores a hash of its data ranges, built hierarchically.
To dive deep into Merkle trees, you can read this.
When two nodes want to compare data, they:
Exchange their Merkle trees (not the raw data).
Compare hashes from the root down.
If a mismatch is detected in a subtree, only that range is checked and synced.
Decision: Design for failure-first, assume parts of the system are always broken and make recovery seamless.
Each of the above topics deserves its own separate post. I have tried to give a brief idea about them, and we can explore them in more detail later.
4. Fast Reads
To be fair, this one is the trickiest; that’s why I have mentioned it last.
If our database is designed for write-heavy operations, certainly, we can’t provide fast reads, not in the sense that other databases provide.
But our use case is different; we don’t need a full text-based search, we only need key-based searches. Let’s understand what kind of queries we will tackle for our index searches.
Get all my chats from the last 30 days
Get the latest 100 messages from my conversation with someone else
Certainly, there will be more queries, but these will constitute 90% of all our queries. These are not full searches, but they are based on keys, especially keys like userId, conversationId, timestamp.
Decision - We don’t design our queries based on our tables; we design our tables based on our queries. And that’s the whole philosophy while working with Cassandra.
If we get our data model wrong, reads can become expensive, scanning multiple SSTables or even partitions.
Don’t worry, we will revisit this part later.
Final decisions
Let’s recap what decisions we took —
Using LSM trees for fast writes
Consistent hashing for partitioning, gossip for coordination, and a tunable replication model
Failure-first design, data sync strategies
Design tables based on queries, and not the other way around
These aren’t just decisions; they’re the pillars on which Cassandra stands.
To be continued…
We will take a pause here, let all of this soak. Cassandra is a masterpiece when it comes to designing a distributed system with its consistent hashing, gossip protocol, and tunable consistency.
Then the algorithms it uses to be highly available are fascinating. It deserves more than a single post to truly understand the scale of Cassandra, the philosophy, and its internals.
So, we will build the intuition on how Cassandra works with all these systems in the next post. We will look at partition keys and clustering keys. How to design a schema in Cassandra for our queries, based on a real-life example.
Till then, stay tuned, and thanks for reading.